- 标签
- 热门文章
- 推荐文章
Gurobi并行计算的设置和操作
Gurobi 是目前被科研学术界和企业界广泛采用的数学规划求解器,不但内置了多种先进算法,也保持了对计算机前沿硬件技术的密切跟踪。随着计算机硬件配置升级,计算能力不断提升,利用最新计算机硬件系统进行并行计算,已经是提升算法整体效率的不可缺少的方法。并行计算不但可以发生在单台电脑中的多核多线程当中,也可以发生在多台计算机组成的集群或者网络中。针对不同的硬件配置,以及不同的算法参数设置,Gurobi 用户可以创建多种并行计算方法。
Gurobi 在官网上提供了在算法设计层面不同算法(单纯形法,内点法,分支定界法等)和并行计算的紧密关系和适用程度的说明。
在这篇文章中,我们将从设置和操作的层面,介绍Gurobi几个并行计算的应用场景,解释一些并行计算的概念和操作方法。为了说明方便,我们归纳一张表格,显示了一个模型或者多个模型在一台电脑上,或者多台电脑集群上进行并行计算的方式。我们以混合整数模型为例。

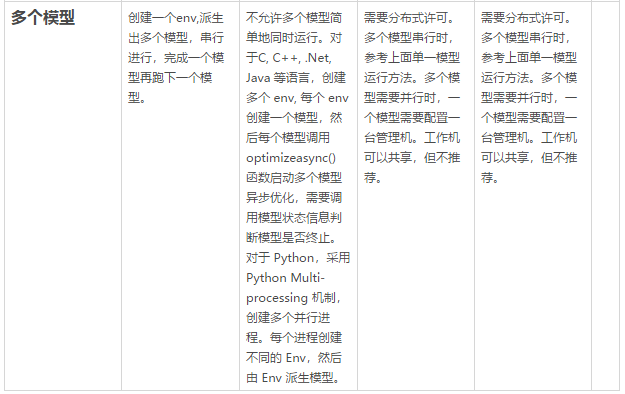
一台机器内单发
这是目前最常见的使用方式。
(1)一个模型:大部分情况下,Gurobi用户创建环境对象 Env(Python语言提供默认的环境对象,用户无需显性定义),然后由Env 产生一个模型对象,用户对于这个模型对象进行各种变量、约束和目标的添加和修改,最终通过运行 optimize()函数启动单个模型的优化。当模型优化时,Gurobi会自动根据模型结构、求解阶段和Threads等参数设置来决定使用一个或者多个线程。用户无需做额外过多设置,这个模型就已经在调用Gurobi内部的并行计算算法。
(2)多个模型:一个Env对象可以产生多个模型对象,在Gurobi 中不允许多个模型简单的同时并行计算,会产生不可预见的错误。用户可以依次串行运行,一个模型运行结束之后再运行另外一个模型。
一台机器内并发
(1)一个模型:Gurobi 允许在一台电脑内通过设置ConcurrentMIP参数,运行同一个模型的多个复制模型。这样的好处是用户可以为不同的复制模型设置不同的优化参数。多个复制模型在不同参数设置下同时运行,胜者决定最终速度。例如一台机器的核数是16核,ConcurrentMIP = 4,那么就会同时有4个同样的模型运行,每个模型占用4个核。
(2)多个模型:之前提到在Gurobi 中不允许多个模型简单的同时并行计算。当多个不同模型同时运行时,如果开发语言是C,Java,C++,.Net 等高级语言,可以采用Gurobi的异步优化函数;如果开发语言是Python,则可以利用Python的多并发进程模块。具体使用方式如下。
如果开发语言是C,Java,C++,.Net 等高级语言,可以采用Gurobi的异步优化函数。当有多个模型时,需要为每个模型创建一个环境对象 Env,由该环境对象产生对应的模型,构造模型之后,调用optimizeasync()启动异步优化。Gurobi不用等优化结束,会将语句控制权直接跳到下个语句,用户可以启动第二、第三或者多个模型。用户可以不断查看模型当前优化状态,来判断模型优化是否结束。优化结束后,需要调用sync()函数进行同步化,之后才能删除模型和环境对象。以下是一个Java 示范案例。
/* Gurobi Example for Running Multiple Models in Parallel */
import gurobi.*;
public class GurobiParallel {
public static void main(String[] args) {
try {
// Create three environments and start. One environment for one model
GRBEnv env1 = new GRBEnv(true);
env1.start();
GRBEnv env2 = new GRBEnv(true);
env2.start();
GRBEnv env3 = new GRBEnv(true);
env3.start();
// Create three models from mps files
GRBModel model1 = new GRBModel(env1, "misc07.mps");
GRBModel model2 = new GRBModel(env2, "glass4.mps");
GRBModel model3 = new GRBModel(env3, "p0033.mps");
// Set up parameters
model1.set(GRB.IntParam.Threads, 1);
model2.set(GRB.IntParam.Threads, 2);
model3.set(GRB.IntParam.Threads, 1);
// Start optimization
model1.optimizeasync();
model2.optimizeasync();
model3.optimizeasync();
// Check optimization status
while(true){
int completed = 0;
int status1 = model1.get(GRB.IntAttr.Status);
if (status1 != GRB.Status.INPROGRESS) {
System.out.println("Model 1 is completed!");
System.out.println("The optimal objective is " +
model1.get(GRB.DoubleAttr.ObjVal));
completed ++;
}
int status2 = model2.get(GRB.IntAttr.Status);
if (status2 != GRB.Status.INPROGRESS) {
System.out.println("Model 2 is completed!");
System.out.println("The optimal objective is " +
model2.get(GRB.DoubleAttr.ObjVal));
completed ++;
}
int status3 = model3.get(GRB.IntAttr.Status);
if (status3 != GRB.Status.INPROGRESS) {
System.out.println("Model 3 is completed!");
System.out.println("The optimal objective is " +
model3.get(GRB.DoubleAttr.ObjVal));
completed ++;
}
if (completed == 3) break;
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
model1.sync();
model2.sync();
model3.sync();
model1.dispose();
env1.dispose();
model2.dispose();
env2.dispose();
model3.dispose();
env3.dispose();
} catch (GRBException e) {
System.out.println("Error code: " + e.getErrorCode() + ". " +
e.getMessage());
}
}
}
如果开发语言是Python,则可以利用Python的多并发进程模块,为每个进程创建一个 Env 对象,然后由Env 产生模型。多个模型在不同的进程内同时运行。以下是一个Python 示范案例。
import multiprocessing as mp
import gurobipy as gp
def solve_model(input_data):
with gp.Env() as env, gp.Model(env=env) as model:
# define model
model.optimize()
# retrieve data from model
if __name__ == '__main__':
with mp.Pool() as pool:
pool.map(solve_model, [input_data1, input_data2, input_data3]
多台机器间分布(集群计算)
分布计算意味着多个计算资源共同运行同一个模型,而非一个模型的多个复制模型。对于基于分支定界的Gurobi 混合整数模型而言,意味着多个计算资源作用于同一个搜索树的不同分支部分,相互协调。当模型的分支节点数量较大时,多台机器或者集群机可以有效地分担计算负载,加快搜索速度,提升求解模型的效率。
很多科研和企业配备有计算机集群,或者有数十台高性能计算机组成的计算网络,这些资源可以用来进行Gurobi分布式计算,增强复杂模型的计算能力。不论求解一个模型,还是多个模型,任何需要多台机器相互协调、分担负载、相互连通、同时运算的使用方式,都需要Gurobi的特殊分布式插件许可。
Gurobi 分布式计算需要配置一台管理机和多台工作机。管理机用于启动优化任务、配置工作机优化资源、协调和决定优化结果。而工作机则用于参与到分布式计算中。一般情况下,一台管理机启动一个优化任务。如果需要同时启动多个优化任务(多个并发模型),则需要配置多台管理机。
(1)一个模型:在管理机上设置 DistributedMIPJOb 参数,启动模型优化任务,让多台工作机共同运行一个模型。这是典型的分布式计算方式。
(2)多个模型:如果多个模型串行时,可以参考上面单一模型运行方法,在管理机上依次串行启动模型。如果多个模型需要并行时,一个模型需要配置一台管理机。工作机可以共享,但不推荐。
多台机器间并发
除了让多台工作机运算同一个分支树的不同部分,Gurobi 分布式许可也允许每台工作机采用不同优化参数运行同一个模型的完整复制模型,哪台工作机速度快,哪台决定最终结果。
(1)一个模型:在管理机上设置ConcurrentJobs 参数,启动模型优化任务,让多台工作机的每台机器跑同一个模型的复制模型。
(2)多个模型:如果多个模型串行时,可以参考上面单一模型运行方法,在管理机上依次串行启动模型。如果多个模型需要并行时,一个模型需要配置一台管理机。工作机可以共享,但不推荐。
总结:Gurobi 提供了多种灵活方式进行单发、并发和分布式计算。用户可以结合模型的特点,以及可调用的计算资源,进行配置和操作。




 沪公网安备31011302006932号
沪公网安备31011302006932号