- 标签
- 热门文章
- 推荐文章
GraphPad Prism双因素方差分析
双向方差分析,也称为双因素方差分析,确定了一个反应如何受到两个因素的影响。例如,您可以测量男性和女性对三种不同药物的反应。药物治疗是一个因素,性别是另一个因素。药物会影响反应吗?按性别?这两者是否交织在一起?这些都是双因素方差分析能回答的问题。
统计新手注意事项
我们使用Prism的目标一直是使基本的生物统计学非常容易获得。双因素方差分析正在突破“基础生物统计学”的极限。双因素方差分析后的多次比较进一步扩展了这一定义。如果您没有花时间真正理解双因素方差分析,很容易被结果误导。小心!
决定哪个因素定义行,哪个定义列?
双因素方差分析不是一个容易掌握的概论。除了阅读课本,也要考虑向更有经验的人寻求帮助。
Prism还为重复测量数据提供了一个混合模型,完全理解这一点就更加复杂了。
在陷入多重比较的众多选择之前,首先要清楚地阐明这项研究的科学目标。不要用方差分析(寻找相互作用)来表述您的目标,避免使用“重要”这个词,因为它经常会导致思维混乱。找出您真正想知道的。然后找出最好的统计方法来得到答案。
决定哪个因素定义行,哪个定义列?
在分组表中输入数据的两种方法
在分组表中,每个数据集(列)代表一个因素的不同级别,每行代表另一个因素的不同级别。
您需要决定哪些因子按行定义,哪些因子按数据集列定义。例如,如果您在三个时间点比较男性和女性,有两种方法来组织数据:
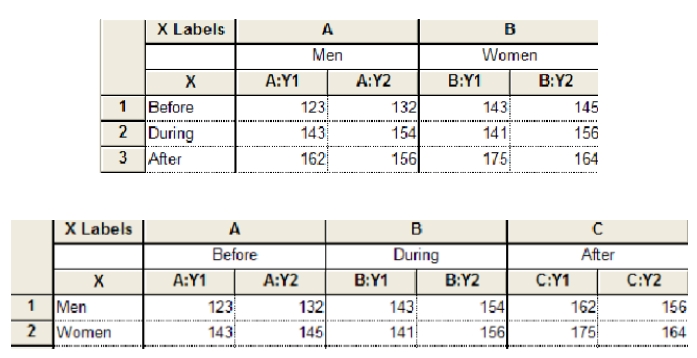
您的选择会影响图形的外观
无论您以何种方式输入数据,方差分析的结果都是相同的。但是这个选项定义了图形的显示方式。如果按照上面第一种方法输入数据,男性和女性将出现在不同颜色的条形图中,每种颜色的三个条形图代表三个时间点(下图左)。如果您使用上面所示的第二种方法输入数据,将会有一种颜色和填充用于Before,另一种用于During,另一种用于After(下图右)。男人和女人看起来像两个相同的条形图。
用转置分析改变您的想法
如果在使用上述选择之一输入和分析数据后,您意识到您希望以另一种方式进行操作,会发生什么?您不需要重新输入您的数据。而是使用Prism的转置分析,然后从结果表中创建一个图。
输入数据进行双因素方差分析(非重复测量)
组由行和列定义
Prism组织双因素方差分析的数据与大多数其他程序不同。
Prism不使用分组变量。相反,使用行和列来指定每个因素的不同组(级别)。每个数据集(列)代表一个因素的不同级别,每行代表另一个因素的不同级别。
设置数据表
从Welcome(或NewDataTableandGraph)对话框中,选择Grouped选项卡。
输入原始数据
创建一个分组表,其中有足够的子列来容纳最大数量的重复数。
在上面的例子中,两行编码一个因子的两个水平(血清饥饿vs.正常培养),三个数据集列编码另一个因子(细胞系)的三个水平。
输入平均数据
如果您已经在另一个程序中平均了您的重复,您可以选择输入并绘制平均值、SD(或SEM)和n。如果您的数据有超过256个重复,这是将数据输入Prism进行双因素方差分析的唯一方法。
注意,重复测量方差分析需要原始数据。这不是Prism的独特要求,而是重复测量分析的基础。因此,如果您输入平均值,样本量和SD或SEM,您只能做普通(不重复测量)方差分析。
输入单个值
如果每个条件只有一个值,则创建一个分组表并选择输入单个Y值(没有子列)。在这种情况下,Prism将只能计算普通(不重复测量)方差分析,并将假设行和列因素之间没有相互作用。它不能在没有重复的情况下测试交互,所以简单地假设没有。对于您的情况,这可能是一个合理的假设,也可能不是。
运行ANOVA
从数据表中,单击分析工具栏。
从分组分析列表中选择双因素方差分析。
由于数据没有重复测量,所以不要在第一个选项卡上选择任何一个选项(RMDesign)。如果没有重复的度量,第二个(RMAnalysis)选项卡上就没有可用的选择。
在第三个(FactorNames)选项卡上,可选地命名定义行和列的分组变量。对于上面显示的示例,您可以将列标记为“细胞系”,将行标记为“血清”。
在第四个(MultipleComparisons)选项卡上,选择您的目标(如果有的话)进行多重比较。
在第五个(Options)选项卡上,选择您想要的多个比较测试的详细信息。
在最后一个(Residuals)选项卡上,选择是否以及如何绘制残差,以及是否要测试它们的正态性和相等的变异性(均方差)。
Prism无法对庞大的数据集进行双因素方差分析
Prism不能运行普通的(不重复测量)巨大数据集的双因素方差分析,并呈现一个消息告诉您。
输入重复测量数据
重复测量是指从每个参与者那里收集因变量的多次测量的实验。重复可以跨越时间(如:之前/之后),跨越不同的条件(例如:高温和低温),或跨越空间(例如:左膝和右膝)。关键问题是,同一个参与者有多个反应。
重复测量数据的分析与使用配对或匹配受试者的随机分组实验的分析相同。在这种情况下,将配对或匹配本身视为“参与者”。当其中一个因素重复或匹配(混合效应)或两个因素都重复时,Prism可以计算重复测量的双因素方差分析。换句话说,Prism可以通过其双因素方差分析处理这三种情况:
两个主体间变量(两个因素都不是重复测量)
一个是主体间变量,一个是主体内变量
两个主题内变量(两个因素都是重复测量)
一个数据表可以对应四个实验设计
Prism使用一种独特的方式输入数据。使用行和列来指定每个因素的不同组(级别)。每个数据集(列)代表一个因素的不同级别,每行代表另一个因素的不同级别。您需要决定哪些因子是按行定义的,哪些是按列定义的。您的选择不会影响方差分析的结果,但选择是重要的,因为它会影响图形的外观。
上表显示了在对照和治疗动物中测试三种剂量药物效果的示例数据。
这些数据可能来自四种不同的实验设计。
不重复测量
也许对上表最简单的解释之一是,这个实验是用12只动物进行的,每只动物测量一次。在这种情况下,每个细胞代表一种不同的动物。当然,这不会是一个重复的测量实验。
另一种情况可能是,产生上述数据的实验是用六只动物进行的。假设每个治疗组合只有一只动物,并且测量是重复的(每只动物测量两次)。在这种情况下,第1行A列中的值:Y1(23)来自与第1行A列中的值:Y2(24)是相同的动物。每种动物的这些重复值被称为伪重复。在用Prism分析这类实验的数据时,由于伪重复的问题,您必须小心。在这种情况下执行标准的双因素方差分析(没有数据处理)会提供误导性的结果。Prism会认为总共有12只动物(如上所述),而不是6只。正因为如此,Prism会假设伪重复之间的差异代表动物之间的差异。然而,在这个实验设计中,伪重复之间的变异实际上代表了动物内部的变异。这是一个重要的问题,有许多方法可以处理它(例如在分析数据之前平均伪重复)。如果您的实验设计包括伪重复,请务必了解它们与标准重复的区别,并在分析中采取适当的措施来考虑它们。
匹配的值分布在一行中
实验用6只动物进行,每次剂量2只。首先在所有6只动物中测量控制值。然后您对所有的动物进行治疗,并再次进行测量。在上表中,第1行A列的值Y1(23)与第1行B列的值Y1(28)来自同一动物。匹配是按行进行的。
匹配的值被堆叠到一个子列中
这个实验是用四只动物做的。首先,每只动物都接受了治疗(或安慰剂)。在测量基线数据(剂量=0)后,注射第一剂并再次进行测量。然后注射第二剂,再次测量。第一个Y1列(23、34和43)的值为同一动物的重复测量值。另外三个子列来自另外三个动物。按列进行匹配。
当每个子列代表一个动物或参与者时,Prism允许您在数据表上标记子列。只需双击子列标题(A:Y1)。
重复测量这两个因素
这个实验是用两只动物做的。首先测量基线(对照,零剂量)。然后注射剂量1,进行下一次测量,然后注射剂量2,再次测量。然后对动物进行实验治疗,等待一段适当的时间,再进行三次测量。最后,您用另一只动物(Y2)重复这个实验。因此,单个动物提供了来自Y1子列(23、34、43和28、41、56)的数据。
当每个子列代表一个动物或参与者时,Prism允许您在数据表上标记子列。只需双击子列标题(A:Y1)。
何时指定哪个设计适用于这个实验?
上面的例子表明,一个分组数据集可以代表四种不同的实验设计。在创建数据表时,不需要区分这些设计。数据表并不“知道”数据是否为重复度量。在选择如何绘制数据图时,您应该考虑到实验设计。在进行双因素方差分析时,必须考虑到这一点。在双因素方差分析对话框的第一个选项卡上,您将指定实验设计。
Lingo:“重复测量”vs“随机分组”实验
当您对每个受试者进行重复测量时,项repeatedmeasures是恰当的。
有些实验包括匹配但不重复的测量。项randomized-block描述了这类实验。例如,假设这三行是三个不同的细胞系。所有的Y1数据来自一个实验,所有的Y2数据来自一个月后的另一个实验。第1行A列Y1(23)和第1行B列Y1(28)的值来自同一实验(相同的细胞传代,相同的试剂)。匹配是按行进行的。
随机分组数据与重复测量数据的分析方法相同。Prism总是使用重复测量这个项,所以当您的实验遵循随机分组设计时,您应该选择重复测量分析。
运行ANOVA
从数据表中,单击分析工具栏。
从分组分析列表中选择双因素方差分析。
在第一个选项卡(RM设计)上选择您的实验设计。
在第二个(RM分析)选项卡上,选择是否要运行重复测量ANOVA或混合模型。
在第三个(FactorNames)选项卡上,可选地命名定义行和列的分组变量。对于上面显示的示例,您可以将列标记为“治疗”,将行标记为“剂量”。每个匹配的集合可以命名为“动物”。
在第四个(MultipleComparisons)选项卡上,选择您的目标(如果有的话)进行多重比较。
在第五个(Options)选项卡上,选择您想要的多个比较测试的详细信息。
在最后一个(Residuals)选项卡上,选择是否以及如何绘制残差,以及是否要测试它们的正态性和相等变异性(均方差)。
图表数据为双因素重复测量方差分析
当用重复测量的数据绘制图表时,选择一个连接代表单个点的符号的图表,以便图表显示数据的性质。为此,选择NewGraph对话框的“individualvalues”选项卡,然后选择右边两种图形类型中的一种。下面的示例显示了用于选择匹配值是否分布在一行中的图表。右边的下一个图显示的是匹配值堆叠的情况。如果在两个方向上都有匹配,则需要选择绘制哪个,因为没有图形(无论如何在Prism中)可以显示两个分组变量中的匹配。
Prism无法在庞大的数据集上运行重复测量的双因素方差分析
Prism不能运行重复测量双因素方差分析与庞大的数据集,并呈现一个消息告诉您。Howhugeishuge?Reallybig!
每一列表示一个不同的时间点,因此匹配的值分布在一行中
Prism无法分析(行数)2次方*列数*子列数*(列数+子列数)>268,435,456的表
每一行代表一个不同的时间点,因此匹配的值被堆叠到一个子列中
Prism无法分析如下表:行数*(列数)2次方*子列数*(行数+子列数)>268,435,456
两个因素的重复测量
Prism可以处理任何可输入的表。
缺失值和双因素方差分析
用普通(非重复测量)方差分析缺失值
注意,有一个值是空的。有一些缺失值是可以的,但是为了适应完整的模型(列效应、行效应和列/行交互),必须在每个数据集的每行中至少有一个值。
由于没有治疗女性的数据,下表不能使用完整模型进行双因素方差分析。每个单元格必须至少有一个值。但是,如果您选择拟合仅主要效应的模型,Prism仍然能够分析该数据(不包括交互项)。
如果您输入的是mean,SD(或SEM)和n,如果n并不总是相同,那是可以的,但是如果您留下n空白或输入0,ANOVA将不起作用。
用重复测量方差分析缺失值
缺失值和重复测量双因素方差分析有两种不同的情况:
Prism可以计算重复测量的双因素方差分析,如果治疗组有不同数量的参与者,但每个参与者(实验,垃圾,…)在每次重复时都有数据。
Prism(从Prism8开始)也可以做重复测量的等效双因素方差分析,如果一些重复的值丢失,只要没有太多的点丢失,它们完全是随机丢失的。如果一些值因为太大而无法测量而丢失,那么任何结果都将是无意义的,因为丢失的值实际上代表表中的最大值。但是,如果一些值完全是随机丢失的,Prism使用一个可以拟合的混合效应模型。
上一条:Aspose使用方法
下一条:aspose插件费用




 沪公网安备31011302006932号
沪公网安备31011302006932号