- 标签
- 热门文章
- 推荐文章
GraphPad Prism v10.3 更新
Welcome to Prism10.3.0!
更先进的统计方法、机器学习算法、新的令人惊叹的可视化。来看看这个版本的Prism:
分层聚类:揭示数据中观察结果之间的自然联系。这种机器学习技术允许您调查不同的观察结果彼此之间的关系有多密切,并发现数据中的分组。
K-means聚类:指定一个目标数量的聚类,这个机器学习算法将划分您的数据,迭代地将最相似的观察分组在一起,并调整聚类分配。
树状图:从聚类分析中可视化层次关系。使用树形图作为一个独立的图或作为热图的一部分,从层次聚类的输出。
置信椭圆和凸包:直观地表示对定义您从中绘制数据的总体的参数的估计,或清楚地指示图表上数据组的边界。
非线性回归的文本渲染方程:从非线性回归中添加高质量的格式化方程到您的图形。在绘图曲线旁边插入包含最佳拟合参数值的公式。
分层聚类
Hierarchical Clustering
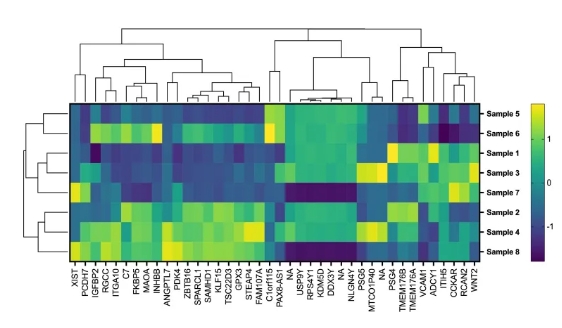
两种新的机器学习算法之一,用于调查数据中的观察组或集群。分层聚类构建关系的树状结构,显示数据中的每个观察值与其他观察值或组的相似或不同之处。将结果可视化为聚集的热图或单独的树形图。
[需要企业版许可证]
K-means聚类
K-means Clustering
在Prism10.3.0中引入的第二种机器学习算法是分层聚类。指定要用数据分析的特定数量的集群或集群范围,Prism将迭代地优化数据中的每个观察值的集群分配。
[需要企业版许可证]
树状图
Dendrograms
可视化作为分层聚类分析一部分的组之间的关系。通过为树状图指定特定数量的簇或切割高度来自定义图形。
[需要企业版许可证]
置信椭圆和凸包
ConfidenceEllipsesandConvexHulls
通过在多变量图中添加置信椭圆或凸包来增强聚类分析的结果,或简单地突出显示数据集中的组。置信椭圆是指示总体参数值(如平均值)的预期位置的好方法,而凸包是在图上显示组边界的绝佳选择。
[需要企业版许可证]
非线性回归的文本渲染方程
TeX-renderedequations
Prism中的非线性回归允许您通过确定所选模型的最佳拟合参数值来拟合数据曲线。绘制这条曲线可以让您演示所记录数据中的非线性关系。现在,您可以直接在图形上显示曲线的这些最佳拟合参数值,在一个地方为任何读者提供他们需要的所有信息。
新功能汇总
实现了层次聚类分析
实现k均值聚类分析
为分层聚类和K-means聚类分析添加了新的样本“文件”
实现文本渲染方程
-在非线性回归参数对话框的模型选项卡上增加了TeX表示
-允许将方程的TeX表示从Prism复制到其他应用程序
-允许在插入分析常数对话框中的图上插入拟合模型的TeX表示
上一条:Gurobi工具介绍
下一条:SnapGene 6.0.2版本




 沪公网安备31011302006932号
沪公网安备31011302006932号