- 标签
- 热门文章
- 推荐文章
Starburst软件详细介绍
2022年春节刚过,现代数据技术栈公司Starburst完成2.5亿美金的D轮融资,估值达到33.5亿。从最近一年多的融资看,美国现代数据技术栈公司受到了资本的大力追捧,独角兽产生的速度也在加快。2021年底Airbyte刚刚完成1.5亿美金的B轮融资,估值到15亿美金 - 不让Fivetran独美,Airbyte新晋独角兽。另外据说dbt正在进行D轮融资,预计估值将会达到60亿美金,关于dbt,大家可以参看-海外数据转换工具独角兽 - dbt labs 。 今天我们就来扒一扒Starburst是个什么样的公司?
Starburst公司简介
公司名 - Starburst Data所在地 - 波士顿
成立时间 - 2017年10月创始人- Justin Borgman, Matt Fuller, Martin Traversal, Dain Sundstorm, David Phillips等融资历史2019年11月 A轮融资 2200万美金 Index资本领投2020年6月 B轮融资 4200万美金 Coatue领投2021年1月 C轮融资 1亿美金 A16Z领投 估值12亿美金 2022年2月 D轮融资 2.5亿美金 Alkeon领投 估值33.5亿美金
对于Starburst Data,可能有些人会觉得陌生,似乎是突然冒出来的公司。但是相信对于国内大数据技术圈的同学来讲,有一个开源产品大家都会知道,那就是最早从Facebook大数据团队开源出来的Presto。作为一个非常知名的开源项目,Presto在国内也有不少的用户,比如京东就曾经是Presto的重度用户,并且曾经京东团队在Presto开源社区还有不少的贡献。而Starbust Data就是基于Presto进行商业化的一家公司。
Starburst公司最早由Justin Borgman和Matt Fuller于2017年10月在波士顿创立。Justin Borgman之前在Teradata是副总裁。在Teradata的时候,Justin Borgman就发现了Presto的潜力,并参与到presto社区贡献中。在Teradata之前,Justin Borgman创立了大数据公司Hadapt,并且通过被收购进入了Teradata。
时间来到2018年,因为在开源理念上与facebook的冲突,Presto团队的核心成员Martin Traversal, Dain Sundstorm, David Phillips以及其他一众人员决定离开Facebook,并在2019年1月成立Presto Software Fundation。而因为Starburst Data正在进行Presto商业化,因此最终Presto核心团队的成员加入了Starburst Data。而正是因为Presto核心团队的加入,Starburst开始获得资本的青睐。从2019年11月到2022年2月,短短两年左右的时间,Starburst的估值爆发式增长,最新的这一轮融资估值超过33亿美金,并且正在准备IPO。而公司的营收规模,也在超过每年3倍的增长,估计很快会超过1亿美金。
Trino和Presto的关系
去看Starburst的官方网站,大家会发现Starburst的开源产品似乎不是Presto,而是Trino,这又是什么原因呢? 而在github上,还有prest这个开源项目,这二者现在的关系又是什么呢?我们接下来继续扒一下这个历史。
前面提到了Presto核心团队从Facebook离职后,成立了Presto Software Fundation,开始继续维护Presto开源社区,社区改名为PrestoSQL。但是Presto毕竟是从Facebook的工作中孵化出来的,因此在2019年,Facebook决定使用Linux Fundation建立一个竞争的presto社区-PrestoDB,然后在2019年10月在Linux Fundation下建立了Presto Fundation,并且对Presto这个注册商标进行了声明。在这种情况下,Presto核心团队就不能再使用PrestoSQL这个名字来继续进行Presto社区的开发和维护,于是团队把PrestoSQL改名为Trino,这就是Trino的来历。
基于这个历史,我们可以这么理解为自从Presto核心团队从Facebook离职后,Presto开源项目就产生了分叉,并最终发展为Facebook继续主导的PrestoDB和Starburst主导的Trino。从github的commit情况看,Trino的活跃度明显的高于PrestoDB,实际上这也可以理解,Presto对于Facebook来讲,并没有那么重要,而在大厂做开源,经常地位比较尴尬。对于Starburst则不同,开源就是这个公司的商业模式,因此在投入和重视程度来讲完全不可对比。做同样的东西,创业公司相对大厂似乎是有资源的劣势,但是专注、投入度则远超大厂,这也正是创业的魅力所在。
03
Trino技术特点
接下来我们简单地介绍一下Starburst主导的开源Trino的相关的技术特点。在BI、数据仓库、数据湖、湖仓一体都是什么?我们介绍了数据仓库和数据湖的概念。无论数据仓库、数据湖还是湖仓一体,一个重要的特点是有一个数据集成的过程,也就是数据要从不同的数据源抽取到数据仓库或者数据湖的存储当中。在这个抽取过程中,一般都数据仓库、数据湖都会针对性的进行存储的设计,从而能让自己在数据查询到时候有更好的性能。
但是我们也知道,对于一些SaaS API类型的数据,数据抽取到数据仓库或者数据湖中再使用是必须的,但是对于很多已经存在对象存储、数据库、数据仓库中的数据,如果都把这些数据抽取到一个中心的数据仓库或者数据湖固然方便使用,但是这无疑会有更多的存储的浪费。在大数据技术发展到今天,存储和计算的分离是趋势,因为存储一般保证的是数据不丢失,更易于访问和使用,但是价格相对低廉。而计算则需要足够的弹性,从而保证能够在有SLA要求的时候可以通过更多的计算资源并行计算来降低计算时间。也正是因为这个原因,能够在原始数据上进行计算而不需要把数据搬到一起无疑是一个比较合适的选择,Trino(Presto)就是基于这个思想而进行设计的。下图是Trino(Presto)工作的一个示意图:
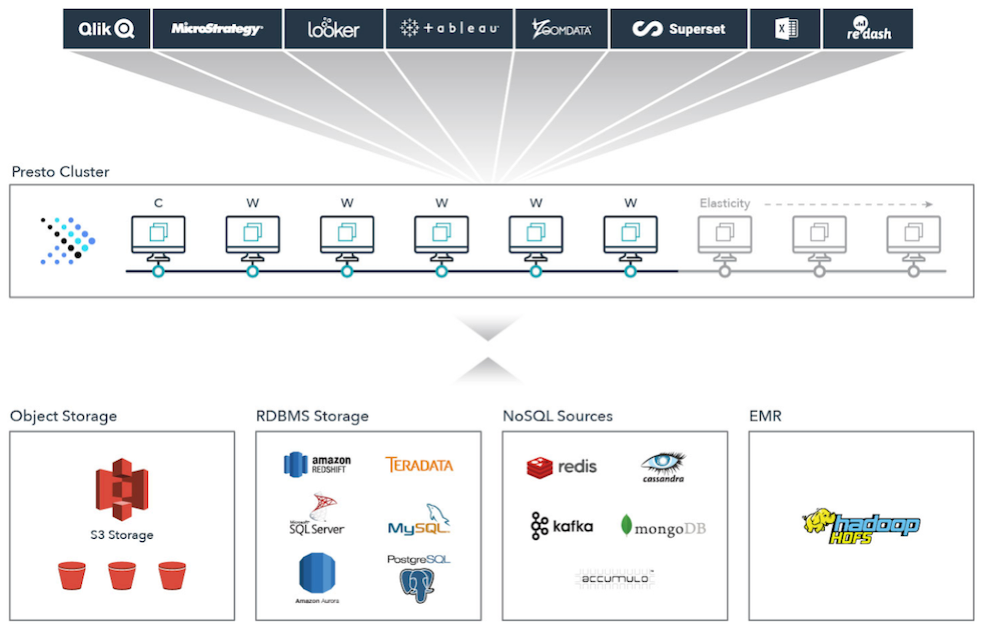
从技术上来讲,Trino是一个MPP(大规模并行处理)数据仓库引擎。相对传统的MPP数据库(Vertica, Greenplum,Hana)来讲,Trino本身只提供计算引擎层,对于数据的访问都是通过connector来连接进行访问的。而且可以根据具体情况将执行下推到具体的数据库或者数据仓库去执行。从这个架构上,实际上与Spark有很多相似的地方。Spark也是一个大规模并行计算的计算引擎,也是可以兼容不同的数据存储。不过Spark和Trino(Presto)的发展路径和使用场景在开始却有很大的不同。
Spark在AMPLab孵化出来之后很快的就发展为了Hadoop Mapreduce的事实上的替代者,因此大部分使用Spark的场景是存储仍旧采用HDFS,但是计算引擎采用Spark。另外,Spark因为其内存模型比较适合迭代类型的计算,因此在很多机器学习的场景都会采用Spark来去实现。另外,Spark推出来的时候,并没有太多考虑SQL的支持,更多面向的是写程序的数据工程师或者数据科学家。大家一般都是采用Scala语言来实现数据处理、数据计算以及机器学习。只是随着用户的发展和放大,Spark开始增加了自己SQL层,一个是能够服务于更多掌握SQL的数据工程师,另外也可以实现SQL的优化能力,从而避免裸写RDD的水平参差不同的问题。发展到后来,Databricks(Spark商业化的公司)发现基于云同时降低使用门槛是商业化的必须的道路,同时结合自己的优点和长处,Databricks最终开始着力发展自己的lakehouse,并且成长为了估值超过350亿美金的七彩独角兽(某位周同学对巨型独角兽的描述)。
再回来看看Trino(Presto),从2012年开始推出来,Presto定位的就是隔离底层的不同数据源的一个分布式计算SQL引擎。底层可以通过connector兼容不同数据库或者数据仓库数据源,上层通过统一的SQL语义封装来方便使用者用SQL提交任务。用户可以直接通过SQL跨多个数据源完成各种分析类型的计算。对于很多数据已经存在不同业务系统数据库或者数据仓库的企业来讲,采用Presto来做分析就减少了数据搬迁的操作,非常方便企业去构建跨多个数据源的分析系统。这也是为什么Presto能够获得非常多的交易型企业的青睐的原因。也正是因为自己的这个特点,Starburst称呼自己的平台为Data Mesh平台。Data Mesh这个概念最早来自于Thoughworks的首席Zhamak Dehghani 发表的博客文章。Starburst对Data Mesh的定义如下:
Data mesh is a new approach based on a modern, distributed architecture for analytical data management. ... Simply put, data mesh makes data accessible, available, discoverable, secure, and interoperable. The faster access to query data directly translates into faster time to value without needing data transportation.
总的来讲,Trino作为一个性能非常不错的MPP架构的计算引擎,在如今企业越来越强烈地使用数据的需求的前提下,的确有自己非常好的应用前景。
04
Starburst的商业化
与大多数目前的Infra公司一样,Starburst采用的也是open core的策略。Trino开源社区目前采用Apache 2.0的授权方式。Starburst基于Trino,有Starburst Enterprice和Starburst Galaxy两个平台。前者通过在开源核心的基础上增加了安全、管理等等能力,另外加上服务卖给一些需要私有化的企业客户。而Starburst Galaxy则是hosting在云上的版本,其定价模式也是采用了现在云原生的Infra公司常见的定价模式-充值然后转为credit(Snowflake模式),然后根据计算来消耗credit。当然,为了能够吸引更多的用户,Starburst Galaxy也有free的入门版本让人去体验。
需要说明一下,Starburst的云版本Galaxy推出的时间不长,不过相信按照云端产品的这种增长潜力,Starburst一定会迎来更好的收入增长,估计也会在不久的将来IPO。
05
总结
利用数据做决策是企业乃至个人都有的诉求,信息技术一路发展过来,实际上是数据做决策的一个迭代的提高过程。最初的关系型数据库的创新让核心交易相关的信息能够记录下来,进而引发了基于企业核心业务数据的第一代BI系统的产生。互联网的发展让用户的行为数据更多的被记录下来,于是产生了方便这些数据被使用的各种非关系型的数据库。在这种背景下,如何更好更方便地利用数据就产生了各种不同的技术路线。Starburst则期待把自己当做那个访问和利用数据的入口,正如其网站所说的,要成为那个"Single point to access data"。我相信未来几年,各种需求一定会促进各种新的技术产品的产生。数据工具作为给人类提供的基于数据做决策的核心产品,必然会有更广阔的发展空间。




 沪公网安备31011302006932号
沪公网安备31011302006932号