- 标签
- 热门文章
- 推荐文章
Grafana一个窗口监控一个组的所有机器CPU和网络情况-大模型提高生产力的典型
背景
前段时间升级了公司的部分机器的网络.
然后其实一个用途是要进行一波次的十几台机器的协同测试
初八加班的时候就是想弄出来
因为挨个去看机器的压力情况太不具体
并且很难同事分析十几台机器的压力情况.
然后我就一直想将压力界面放到一个panel上面
初八加班了很久, 结果失败了.
初九上班,跟建超一起弄,很快发现自己犯错的地方
然后很快解决了CPU的监控
然后初九晚上自己又处置了网络出入口的监控
其中大模型给自己的帮助真的很大, 所以想记录一下
建超因为对监控研究的比较深,帮助也很大.
当然了纯粹是因为我菜
promsql 好多年前我就知道
但是一直没有学精细
grafana也是, 很久就开始学版本都从 5到了12了还没学会.
效果
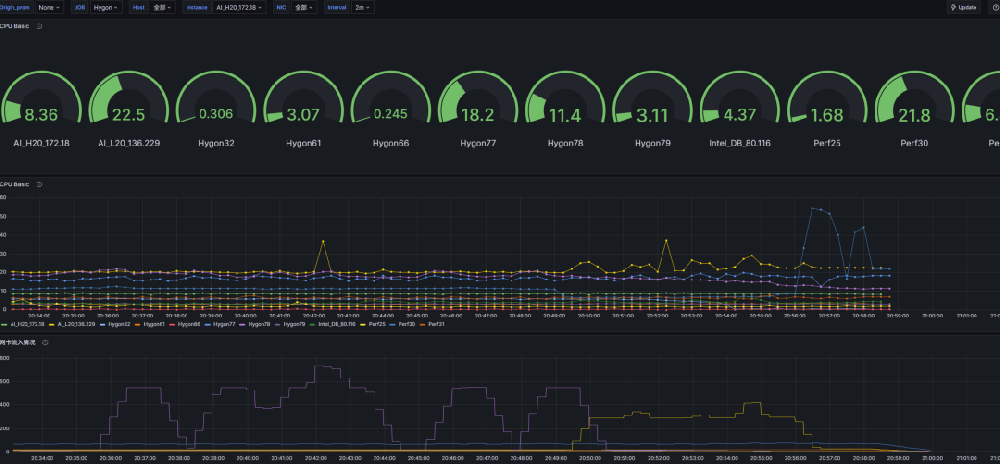
想法原因
虽然CPU的折线图效果可能是最好的.
但是因为涉及十几台机器 用研究去找低的还是动鼠标
所以我还是觉得用gauge可能更好一些.
所以CPU得压力 我用的 gauge的图
然后网络我发现他的获取很难,
因为网络不像是CPU持久性要弱一点点
所以我还是复用了折线图
因为实质上CPU高了,网络大概率也要高
主要是想发现瓶颈的. 所以换用了别的图
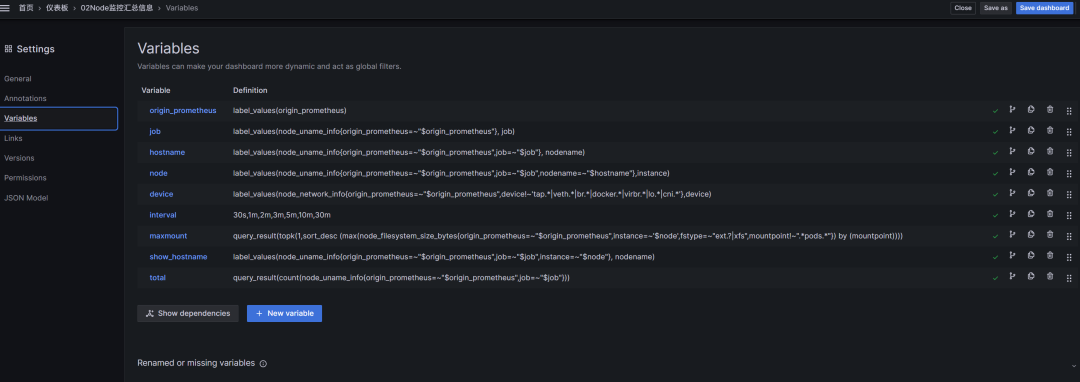
整体处理思路
其实我这边复用了之前的一个panel
https://grafana.com/grafana/dashboards/11074
然后我利用他已经有的变量进行相关的工作
减少工作量.
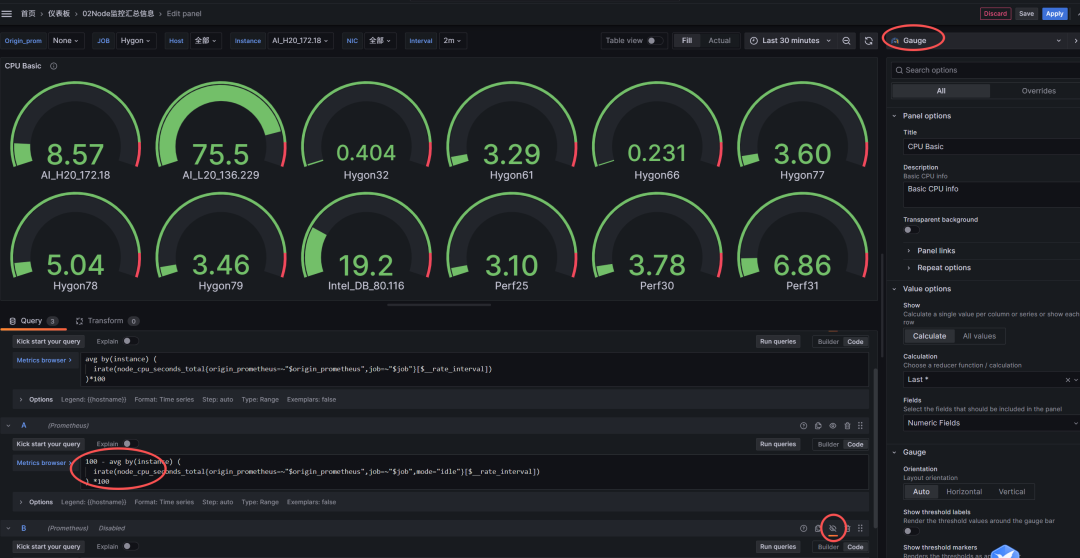
然后新增加panel 进行CPU的设置
获取CPU使用率的PromSQL
100 - avg by(instance) (
irate(node_cpu_seconds_total{origin_prometheus=~"$origin_prometheus",job=~"$job",mode="idle"}[$__rate_interval])
) *100
注意这个是绝对值 100了. 不是百分比.
已经有的变量信息
CPU的处置界面
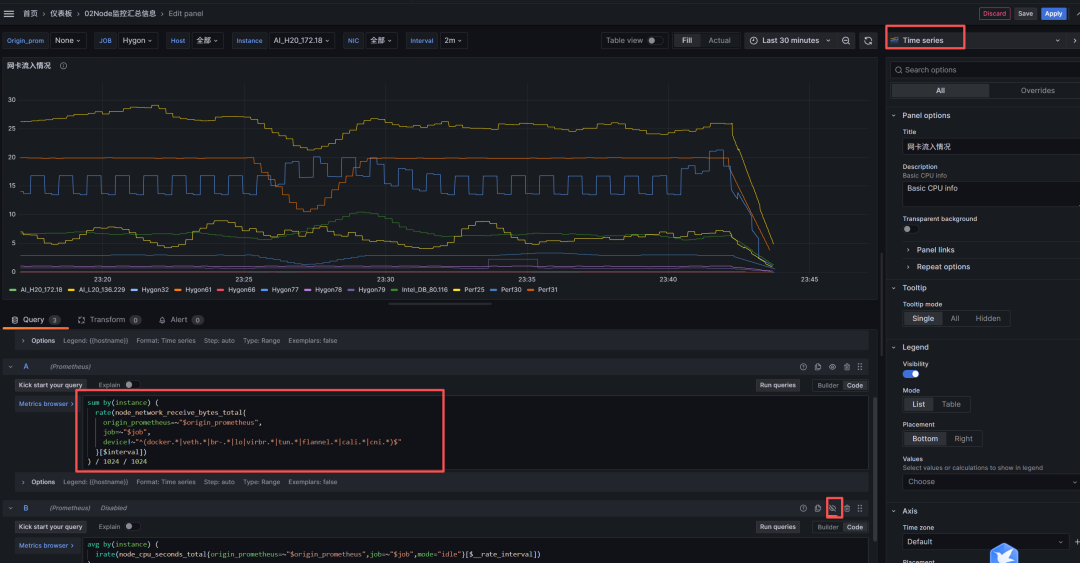
网络的处置
接受和发送分开来的, 想着这样可以分开来看.
注意这里大模型给了很大帮助
因为我这边十几台机器
网卡名字不一样, 有的带容器
有的带bond0 有的还是虚拟机的br0
所以网卡太复杂比较难搞.
使用大模型给出来一个脚本, 可以排除掉虚拟机的
只看物理机的就准确的多了.
sum by(instance) (
rate(node_network_receive_bytes_total{
origin_prometheus=~"$origin_prometheus",
job=~"$job",
device!~"^(docker.*|veth.*|br-.*|lo|virbr.*|tun.*|flannel.*|cali.*|cni.*)$"
}[$interval])
) / 1024 / 1024
sum by(instance) (
rate(node_network_transmit_bytes_total{
origin_prometheus=~"$origin_prometheus",
job=~"$job",
device!~"^(docker.*|veth.*|br-.*|lo|virbr.*|tun.*|flannel.*|cali.*|cni.*)$"
}[$interval])
) / 1024 / 1024
网络监控的部署
下一条:grafana 技巧




 沪公网安备31011302006932号
沪公网安备31011302006932号