- 标签
- 热门文章
- 推荐文章
Toad一个非常好用的标准化评分卡模型工具
Toad是由厚本金融风控团队内部孵化产生的标准评分卡库,使用其相应的子模块进行EDA、分箱、WOE转换、模型特征筛选、模型验证等都非常方便。本文旨在介绍Toad库的基本功能,现将过程记录下来,仅供参考。
1准备数据
该数据来源于某银行个人贷款违约预测数据集,个别字段有做了脱敏(金融的数据大都涉及机密)。主要的特征字段有个人基本信息、经济能力、贷款历史信息等等。数据有10000条样本,38维原始特征,其中isDefault为标签,是否逾期违约。字段说明如下:
字段 字段描述
loan_id贷款记录唯一标识
user_id借款人唯一标识
total_loan贷款数额
year_of_loan贷款年份
interest当前贷款利率
monthly_payment分期付款金额
grade贷款级别
employment_type所在公司类型(世界五百强、国有企业、普通企业…)
industry工作领域(传统工业、商业、互联网、金融…)
work_year工作年限
home_exist是否有房
censor_status审核情况
issue_month贷款发放的月份
use贷款用途类别
post_code贷款人申请时邮政编码
region地区编码
debt_loan_ratio债务收入比
del_in_18month借款人过去18个月逾期30天以上的违约事件数
scoring_low借款人在贷款评分中所属的下限范围
scoring_high借款人在贷款评分中所属的上限范围
known_outstanding_loan借款人档案中未结信用额度的数量
known_dero贬损公共记录的数量
pub_dero_bankrup公开记录清除的数量
recircle_bal信贷周转余额合计
recircle_util循环额度利用率
initial_list_status贷款的初始列表状态
app_type是否个人申请
earlies_credit_mon借款人最早报告的信用额度开立的月份
title借款人提供的贷款名称
policy_code公开可用的策略_代码=1新产品不公开可用的策略_代码=2
f系列匿名特征匿名特征f0-f4,为一些贷款人行为计数特征的处理
early_return借款人提前还款次数
early_return_amount贷款人提前还款累积金额
early_return_amount_3mon近3个月内提前还款金额
import pandas as pd
pd.set_option("display.max_columns",50)
train_data = pd.read_csv('./train_public.csv')
print(train_data.shape)
train_data.head()
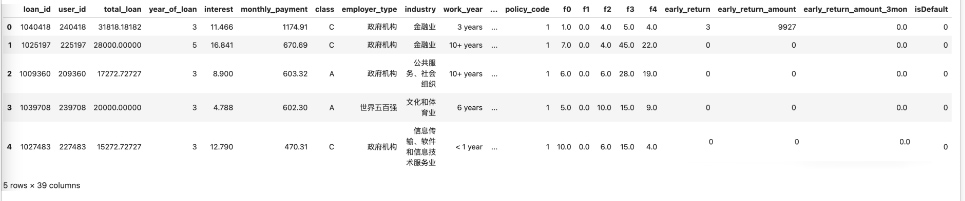
对数据预处理主要是对日期信息、噪音数据做下处理,并划分下类别、
数值类型的特征:
# 日期类型:issueDate 转换为pandas中的日期类型,加工出数值特征
train_data['issue_date'] = pd.to_datetime(train_data['issue_date'])
# 提取多尺度特征
train_data['issue_date_y'] = train_data['issue_date'].dt.year
train_data['issue_date_m'] = train_data['issue_date'].dt.month
# 提取时间diff # 转换为天为单位
base_time = datetime.datetime.strptime('2000-01-01', '%Y-%m-%d') # 随机设置初始的基准时间
train_data['issue_date_diff'] = train_data['issue_date'].apply(lambda x: x-base_time).dt.days
# 可以发现earlies_credit_mon应该是年份-月的格式,这里简单提取年份
train_data['earlies_credit_mon'] = train_data['earlies_credit_mon'].map(lambda x:int(sorted(x.split('-'))[0]))
train_data.head()
# 工作年限处理
train_data['work_year'].fillna('10+ years', inplace=True)
work_year_map = {'10+ years': 10, '2 years': 2, '< 1 year': 0, '3 years': 3, '1 year': 1,
'5 years': 5, '4 years': 4, '6 years': 6, '8 years': 8, '7 years': 7, '9 years': 9}
train_data['work_year'] = train_data['work_year'].map(work_year_map)
train_data['class'] = train_data['class'].map({'A': 0, 'B': 1, 'C': 2, 'D': 3, 'E': 4, 'F': 5, 'G': 6})
# 缺失值处理
train_data = train_data.fillna('9999')
2 EDA数据处理
1. toad.detect(dataframe):
用于检测数据情况(EDA)。输出每列特征的统计性特征和其他信息,主要的信息包括:缺失值、unique values、数值变量的平均值、离散值变量的众数等。相对于describe(),统计更加详细、多元;
数值型变量会返回数据类型、缺失率、唯一值、均值、标准差、分位数等;
分类型变量会返回数据类型、缺失率、唯一值、top1(占比第一的数据类)等。
import toad
toad.detector.detect(train_data)

输出统计列:
toad.detector.detect(train_data).columns
# 统计列如下:
"""
Index(['type', 'size', 'missing', 'unique', 'mean_or_top1', 'std_or_top2','min_or_top3',
'1%_or_top4', '10%_or_top5', '50%_or_bottom5','75%_or_bottom4', '90%_or_bottom3',
'99%_or_bottom2', 'max_or_bottom1'],
dtype='object')
"""
如果只需要统计数值型特征:参数percentiles可根据实际情况删减需要的分位数。
toad.detector.getDescribe(train_data, percentiles=[0.25, 0.5, 0.75])
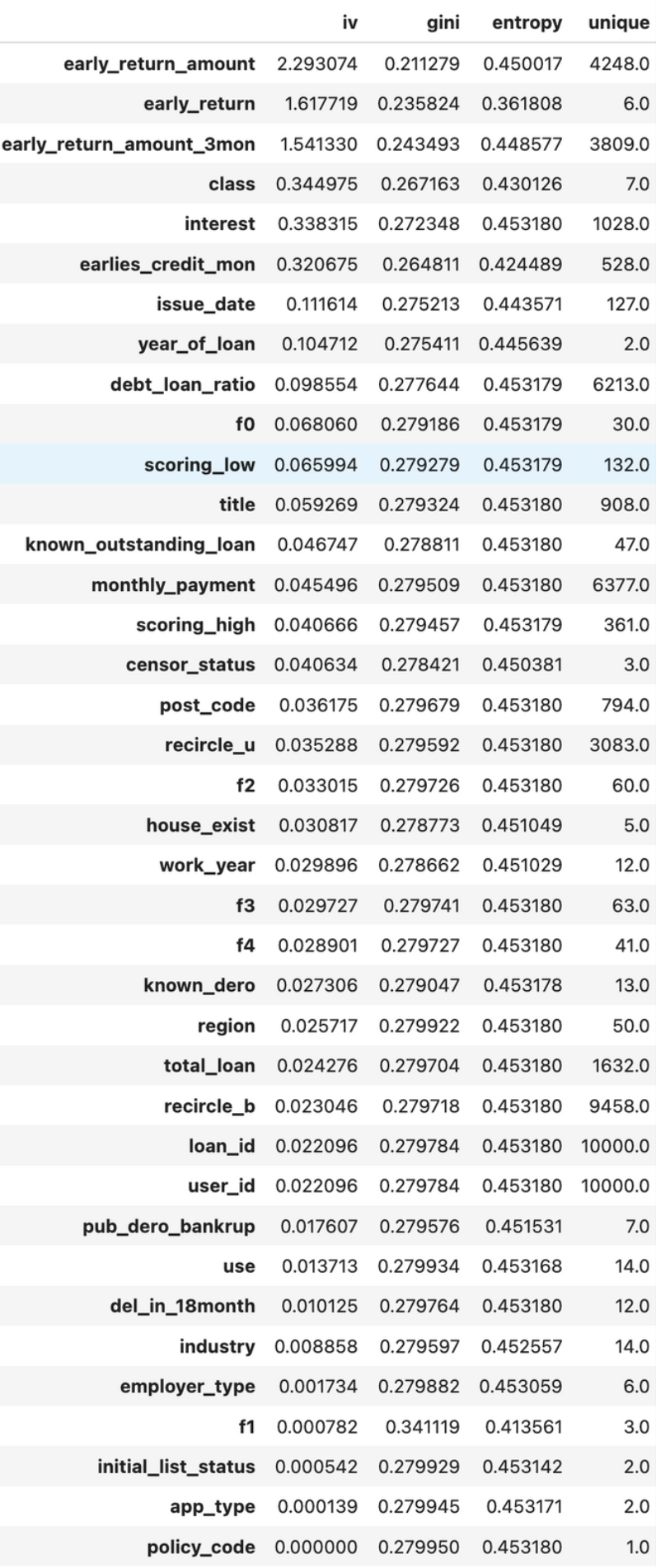
2.toad.quality(dataframe, target=’target’, iv_only=False):
查看数据质量:
输出每个变量的iv值、gini、entropy和unique values,结果以iv值排序。“target”为目标列,“iv_only”决定是否只输出iv值。
注意:
对于数据量大或高维度数据,建议使用iv_only=True
2. 要去掉主键,日期等高unique values且不用于建模的特征
quality = toad.quality(train_data,'isDefault')
quality.sort_values('iv',ascending = False)
特征筛选
toad.selection.select(dataframe, target=’target’)
组合不同评价指标设置阈值来筛选特征:
根据缺失值占比,iv值,和高相关性进行变量筛选
selected_data, drop_list = toad.selection.select(
train_data,
target = 'isDefault', # 标签,是否逾期违约
empty = 0.5, # 若变量的缺失值大于0.5被删除
iv=0.05, # 若变量的iv值小于0.05被删除
corr=0.7, # 若两个相关性高于0.7时,iv值低的变量被删除
return_drop=True, # 若为True,function将返回被删去的变量列
exclude=exclude=['earlies_credit_mon','loan_id','user_id','issue_date']
# 明确不被删去的列名,输入为list格式
)
# selected_data 为筛选的数据,drop_list为删除的数据
如本例子中,empty为缺失值而被删除的特征,
iv为IV值过小被删除的特征,corr为因相关性过高被删除的特征有3个。target = 'isDefault', # 标签,是否逾期违约
drop_list
{'empty': array([], dtype=float64),
'iv': array(['total_loan', 'monthly_payment',
'employer_type', 'industry', 'work_year', 'house_exist',
'censor_status', 'use', 'post_code', 'region', 'del_in_18month',
'scoring_high', 'known_outstanding_loan', 'known_dero',
'pub_dero_bankrup', 'recircle_b', 'recircle_u',
'initial_list_status', 'app_type', 'earlies_credit_mon',
'policy_code', 'f1', 'f2', 'f3', 'f4', 'issue_date_y',
'issue_date_m'], dtype=object),
'corr': array(['interest', 'early_return_amount_3mon'], dtype=object)}
4分箱
toad.transform.Combiner
toad的分箱功能支持数值型数据和离散型分箱,
分箱步骤如下:
1.初始化Combiner对象:
combiner = toad.transform.Combiner()
2.训练分箱fit()方法,选择分箱方式:
combiner.fit(selected_data, y = 'isDefault', method = 'chi', min_samples = 0.05, n_bins = None)
"""
y: 目标列
method: 分箱方法,支持'chi'(卡方分箱), 'dt' (决策树分箱), 'kmean' , 'quantile' (等频分箱), 'step' (等步长分箱)
min_samples: 每箱至少包含样本量,可以是数字或者占比
n_bins: 箱数,若无法分出这么多箱数,则会分出最多的箱数
empty_separate: 是否将空箱单独分开
"""
3.查看分箱节点:
combiner.fit(selected_data, y = 'isDefault', method = 'chi', min_samples = 0.05, n_bins = None)
"""
y: 目标列
method: 分箱方法,支持'chi'(卡方分箱), 'dt' (决策树分箱), 'kmean' , 'quantile' (等频分箱), 'step' (等步长分箱)
min_samples: 每箱至少包含样本量,可以是数字或者占比
n_bins: 箱数,若无法分出这么多箱数,则会分出最多的箱数
empty_separate: 是否将空箱单独分开
"""
4.使用toad.plot ----基于badrate图调整分箱
c.transform(dataframe, labels=False): 分箱结果
labels: 是否将分箱结果转化成箱标签。
False时输出0,1,2…(离散变量根据占比高低排序),
True输出(-inf, 0], (0,10], (10, inf)。
注意:1. 注意删去不需要分箱的列,特别是ID列和时间列
toad.plot的module提供了一部分的可视化功能,
帮助调整分箱节点。
时间内观察 :toad.plot.bin_plot(dataframe, x = None, target = ‘target’)
bar代表了样本量占比,红线代表了正样本占比(e.g. 坏账率) x: 需要观察的特征 target: 目标列
跨时间观察 :toad.plot.badrate_plot(dataframe, target = ‘target’, x = None, by = None)
输出不同时间段中每箱的正样本占比 target: 目标列 x: 时间列, string格式 by: 需要观察的特征
adj_var = 'scoring_low'
adj_bin = {'scoring_low': [565, 600, 622, 660, 670, 745, 775]}
c1 = toad.transform.Combiner()
c1.set_rules(adj_bin)
temp_data = c1.transform(selected_data[['scoring_low','isDefault']], labels=True)
from toad.plot import bin_plot,badrate_plot
bin_plot(temp_data, target = 'isDefault',x=adj_var)
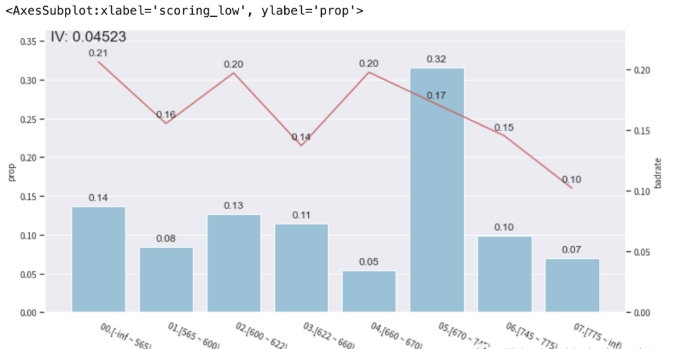
从上图中可以看出bad_rate不单调,对特征分箱进行适当调整,
尝试将第1、2箱,第3、4箱进行合并:
adj_var = 'scoring_low'
adj_bin_2 = {'scoring_low': [565, 622, 690, 775]}
from toad.plot import badrate_plot,bin_plot
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin_2)
# 只对'scoring_low'特征进行调整,没有对所有特征
temp_data_2 = c2.transform(selected_data[['scoring_low','isDefault']], labels=True)
bin_plot(temp_data_2,target='isDefault',x=adj_var)
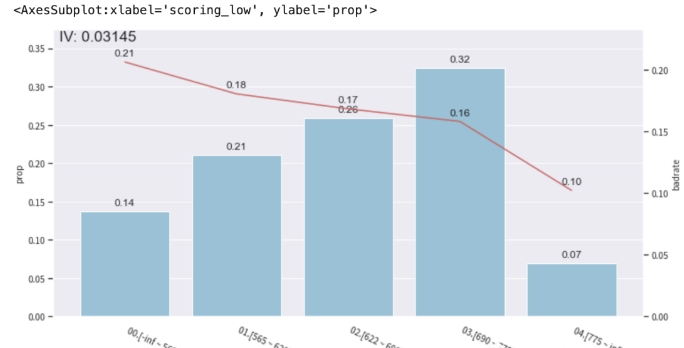
调整之后可以看到分箱的bad_rate整体上呈现我们希望看到的单调的趋势
5WOE转换
接下来就是对各个特征的分箱做WOE编码,
通过WOE编码给各个分箱不同的权重,提升之后LR模型的非线性。
toad.transform.WOETransformer
WOE转化在分箱调整好之后进行,步骤如下:
1.用调整好的Combiner转化数据:
c.transform(dataframe) 只会转化被分箱的变量
#1)设置分箱号
combiner.set_rules(adj_bin_2)
#2)将特征的值转化成分箱的箱号
binned_data = combiner.transform(selected_data)
binned_data
2.初始化woe transer:* transer = toad.transform.WOETransformer()
#3)初始化woe transer对象
transer = toad.transform.WOETransformer()
3.fit_transform:* transer.fit_transform(dataframe, target, exclude = None)
target:目标列数据(非列名)
exclude: 不需要被WOE转化的列 注意:会转化所有列,包括未被分箱transform的列,通过 ‘exclude’ 删去不要WOE转化的列,特别是target列
#4)对WOE的值进行转化,将其映射到原数据集上.
data_train_woe = transer.fit_transform(binned_data, binned_data['isDefault'], exclude=['isDefault'])
data_train_woe
6特征选择
toad.selection.stepwise()
逐步回归特征筛选,支持向前,向后和双向(推荐)
toad.selection.stepwise(dataframe,
target=’target’,
estimator=’ols’, # 用于拟合的模型,支持'ols', 'lr', 'lasso', 'ridge'
direction=’both’, # 逐步回归的方向,支持'forward', 'backward', 'both' (推荐)
criterion=’aic’, # 评判标准,支持'aic', 'bic', 'ks', 'auc'
max_iter=None, # 最大循环次数
return_drop=False,# 是否返回被剔除的列名
exclude=None # 需要被训练的列名,比如ID列和时间列
)
final_data = toad.selection.stepwise(data_train_woe, target='isDefault', direction = 'both', criterion = 'aic')
print(final_data.shape)
print(final_data.columns)
"""
# 经过模型选择,最终有7个特征可作为模型变量
(10000, 8)
Index(['year_of_loan', 'class', 'debt_loan_ratio', 'f0', 'early_return',
'early_return_amount', 'isDefault', 'issue_date_diff'],
dtype='object')
"""
7利用逻辑回归模型建模
1.数据切分
from sklearn.linear_model import LogisticRegression # LR模型
from sklearn.model_selection import train_test_split # 切分数据
# 切分训练集、测试集
train_x,test_x,train_y,test_y = train_test_split(final_data.drop('isDefault',axis=1),final_data['isDefault'],test_size=0.3,random_state=450)
2.训练LR模型
lr = LogisticRegression(class_weight='balanced')
lr.fit(train_x, train_y)
3.模型评估
采用风控模型常用的评估指标:AUC、KS、F1
from toad.metrics import KS, F1, AUC
#1)训练集预测
E_train_proba = lr.predict_proba(train_x)[:,1]
E_train = lr.predict(train_x)
#2)常用的评估指标有F1、KS、AUC
print('F1:', F1(E_train_proba,train_y))
print('KS:', KS(E_train_proba,train_y))
print('AUC:', AUC(E_train_proba,train_y))
"""
F1: 0.28920669844762253
KS: 0.6462134551554157
AUC: 0.8685312716930919
"""
# 测试集预测
E_test_proba = lr.predict_proba(test_x)[:,1]
E_test = lr.predict(test_x)
print('F1:', F1(E_test_proba,test_y))
print('KS:', KS(E_test_proba,test_y))
print('AUC:', AUC(E_test_proba,test_y))
"""
F1: 0.2847341337907376
KS: 0.6688
AUC: 0.8788104000000001
"""
4.模型监控
常用PSI来监控模型的稳定性,比较训练集和测试集的各变量的稳定性
# PSI分为两种,一个是变量的PSI,一个是模型的PSI。
# 监控模型稳定性
psi_model = toad.metrics.PSI(E_train_proba,E_test_proba)
psi_model
"""
0.34896088261308705
"""
# 变量的稳定性
psi_val = toad.metrics.PSI(train_x, test_x)
psi_val.sort_values(0,ascending=False)
"""
class 0.002981
f0 0.001948
debt_loan_ratio 0.001882
issue_date_diff 0.001878
year_of_loan 0.001401
early_return 0.000173
early_return_amount 0.000085
dtype: float64
"""
5.模型预测分箱后评判信息
toad.metrics.KS_bucket(predicted_proba, y_true, bucket=10, method = ‘quantile’)
toad还提供了整个评价指标的汇总,输出模型预测分箱后评判信息,包括每组的分数区间,样本量,坏账率,KS等。
bucket:分箱的数量
method:分箱方法,建议用'quantile'(等人数),或'step' (等分数步长)
train_bucket = toad.metrics.KS_bucket(E_train_proba,train_y,bucket=10,method='quantile')
train_bucket
bad_rate为每组坏账率:(1)组之间的坏账率差距越大越好(2)可以用于观察是否有跳点(3)可以用与找最佳切点(4)可以对比
8转换评分
toad.ScoreCard(combiner={},transer=None,pdo= 60, rate = 2, base_odds = 20, base_score = 750, card = None, C=0.1,kwargs)
最后一步就是将逻辑回归模型转换成标准评分卡,支持传入逻辑回归参数,进行调参。
combiner: 传入训练好的 toad.Combiner 对象
transer: 传入先前训练的 toad.WOETransformer 对象
pdo、rate、base_odds、base_score: e.g. pdo=60, rate=2, base_odds=20, base_score=750 实际意义为当比率为1/20,输出基准评分750,当比率为基准比率2倍时,基准分下降60分
card: 支持传入专家评分卡
**kwargs: 支持传入逻辑回归参数(参数详见 sklearn.linear_model.LogisticRegression)
card = toad.scorecard.ScoreCard(combiner = combiner, transer = transer , C = 0.1)
card.fit(train_x, train_y)
card.export(to_frame = True,)
最终结果如下:
name value score
0 year_of_loan [-inf ~ 5) 83.73
1 year_of_loan [5 ~ inf) 79.57
2 class [-inf ~ 1) 155.83
3 class [1 ~ 2) 109.00
4 class [2 ~ 3) 71.42
5 class [3 ~ 4) 57.31
6 class [4 ~ inf) 24.88
7 debt_loan_ratio [-inf ~ 8.468181818) 100.99
8 debt_loan_ratio [8.468181818 ~ 12.77) 97.88
9 debt_loan_ratio [12.77 ~ 21.48545455) 82.77
10 debt_loan_ratio [21.48545455 ~ 26.73818182) 74.86
11 debt_loan_ratio [26.73818182 ~ inf) 60.49
12 f0 [-inf ~ 7.0) 87.03
13 f0 [7.0 ~ 11.0) 77.86
14 f0 [11.0 ~ inf) 70.60
15 early_return [-inf ~ 1) 87.48
16 early_return [1 ~ inf) 69.83
17 early_return_amount [-inf ~ 51) -20.88
18 early_return_amount [51 ~ 1374) 253.44
19 early_return_amount [1374 ~ inf) 286.21
20 issue_date_diff [-inf ~ 5204) 95.95
21 issue_date_diff [5204 ~ 5569) 84.02
22 issue_date_diff [5569 ~ 5875) 80.59
23 issue_date_diff [5875 ~ 6057) 64.55
24 issue_date_diff [6057 ~ 6514) 78.18
25 issue_date_diff [6514 ~ inf) 101.60
上一条:erwin什么是数据映射?




 沪公网安备31011302006932号
沪公网安备31011302006932号