- 标签
- 热门文章
- 推荐文章
使用toad训练一张评分卡
一、必要的Python第三方库
toad如果出现import错误,可以先把numpy/pandas/toad都卸载掉
然后重装toad
pip uninstall pandas
pip uninstall numpy
pip uninstall toad
pip install toad
二、建模环境准备
import pandas as pd
import numpy as np
import os
import toad
import warnings
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
import xgboost as xgb
from toad.plot import bin_plot, badrate_plot
from toad.metrics import KS, AUC, F1
warnings.filterwarnings('ignore')
# 设置显示数量
pd.set_option('display.max_columns', 5000)
pd.set_option('display.width', 1000)
三、定义双向逻辑回归和检验模型XGBoost
def lr_model(x, y, offx, offy, C):
"""定义逻辑回归"""
model = LogisticRegression(C=C, class_weight='balanced')
model.fit(x, y)
y_pred = model.predict_proba(x)[:, 1]
fpr_dev, tpr_dev, _ = roc_curve(y, y_pred)
train_ks = abs(fpr_dev - tpr_dev).max()
print('train_ks : ', train_ks)
y_pred = model.predict_proba(offx)[:, 1]
fpr_off, tpr_off, _ = roc_curve(offy, y_pred)
off_ks = abs(fpr_off - tpr_off).max()
print('off_ks : ', off_ks)
plt.plot(fpr_dev, tpr_dev, label='train')
plt.plot(fpr_off, tpr_off, label='off')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc='best')
plt.show()
def xgb_model(x, y, offx, offy):
"""定义xgboost辅助判断特征交叉是否有必要"""
model = xgb.XGBClassifier(learning_rate=0.05,
n_estimators=400,
max_depth=3,
class_weight='balanced',
min_child_weight=1,
subsample=1,
objective="binary:logistic",
nthread=-1,
scale_pos_weight=1,
random_state=1,
n_jobs=-1,
reg_lambda=300)
model.fit(x, y)
print('>>>>>>>>>')
y_pred = model.predict_proba(x)[:, 1]
fpr_dev, tpr_dev, _ = roc_curve(y, y_pred)
train_ks = abs(fpr_dev - tpr_dev).max()
print('train_ks : ', train_ks)
y_pred = model.predict_proba(offx)[:, 1]
fpr_off, tpr_off, _ = roc_curve(offy, y_pred)
off_ks = abs(fpr_off - tpr_off).max()
print('off_ks : ', off_ks)
plt.plot(fpr_dev, tpr_dev, label='train')
plt.plot(fpr_off, tpr_off, label='off')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc='best')
plt.show()
def c_train(data, target='y_label', exclude=None, type_name={'train': 'train', 'test': 'test', 'oot': 'oot'},
standardscaler=False):
"""模型训练--双向xgb&lr检验"""
std_scaler = StandardScaler()
# 变量名
lis = list(data.columns)
for i in exclude:
lis.remove(i)
# 数据标准化
if standardscaler:
data[lis] = std_scaler.fit_transform(data[lis])
# 划分数据集
train = data[(data['type'] == type_name['train']) | (data['type'] == type_name['test'])]
oot = data[data['type'] == type_name['oot']]
x, y = train[lis], train[target]
oot_x, oot_y = oot[lis], oot[target]
# 逻辑回归正向
lr_model(x, y, oot_x, oot_y, 0.1)
# 逻辑回归反向
lr_model(oot_x, oot_y, x, y, 0.1)
# XGBoost正向
xgb_model(x, y, oot_x, oot_y)
# XGBoost反向
xgb_model(oot_x, oot_y, x, y)
四、数据准备
# ---------- 基础变量
target = 'target'
# ---------- 读取数据
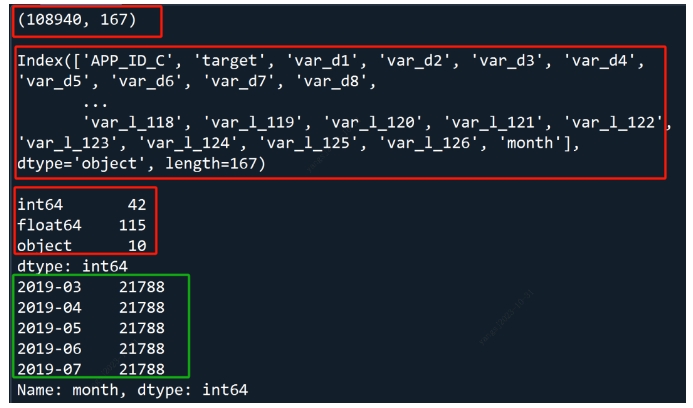
df = pd.read_csv('../data/toad_trainData.csv')
print(df.shape, df.columns, df.dtypes.value_counts().sort_index(), sep='\n\n')
print(df.month.value_counts())
五、样本切分
# ---------- 划分时间外样本
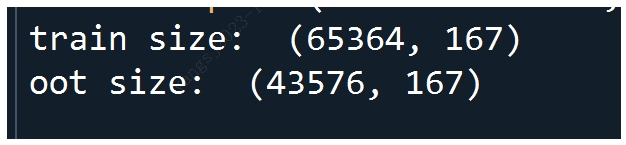
train = df.loc[df.month.isin(['2019-03', '2019-04', '2019-05']) == True]
oot = df.loc[df.month.isin(['2019-03', '2019-04', '2019-05']) == False]
print('train size: ', train.shape, '\noot size: ', oot.shape)
六、EDA
"""
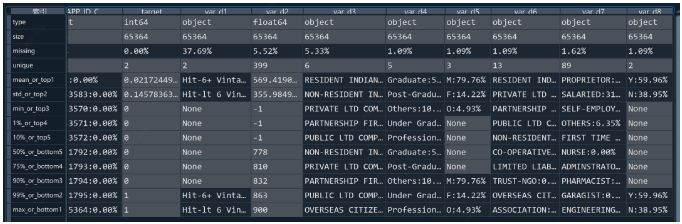
检测数据情况(EDA): 输出每列特征得统计性特征和其他信息
包含:缺失值、unique values、数值变量得平均值、离散值变量得众数等
type : 变量类型;size : 数据集大小;missing : 缺失值比例;unique:唯一值数量
连续型变量依次展示:均值、标准差、最小值、1%、10%、50%、75%、90%、99%、最大值
离散型变量依次展示:top1、top2、top3、top4、top5、bottom5、bottom4、bottom3、bottom2、bottom1
"""
df_describe = toad.detect(train)[:10]
七、查看数据质量
# ---------- 数据质量toad.quality(dataframe, target='target', iv_only=False)
"""
输出每个变量得iv,gini,entropy,unique_values,结果以iv排序。
target:目标变量
iv_onlt:是否只输出iv值
对于数据量大或高维度数据,建议使用iv_only=True
要去掉主键,日期等高unique values且不用于建模的特征
"""
col_drop = ['APP_ID_C', 'month'] # 待删除字段
df_iv = toad.quality(df.drop(columns=col_drop), target=target, iv_only=True, cpu_cores=1)
df_iv[:15]
八、特征筛选
"""
使用iv\empty\corr进行特征筛选
返回筛选后的数据、删除的特征字典
"""
empty = 0.5 # 缺失率高于empty则删除
iv = 0.05 # iv小于阈值则删除
corr = 0.7 # 相关性高于阈值,删除iv小的
return_drop = True # 若为True,将同时返回被删除的变量
exclude = col_drop # 明确不被删除的列名,输入为list格式
train_selected, droped = toad.selection.select(train, target=target, empty=empty, iv=iv, corr=corr,
return_drop=return_drop, exclude=exclude)
print(droped)
print(train_selected.shape)
{
'empty': array([], dtype=float64),
'iv': array(['var_d1', 'var_d4', 'var_d8', 'var_d9', 'var_b6', 'var_b7',
'var_l_1', 'var_l_2', 'var_l_3', 'var_l_4', 'var_l_5', 'var_l_6',
'var_l_7', 'var_l_8', 'var_l_10', 'var_l_11', 'var_l_12',
'var_l_13', 'var_l_14', 'var_l_15', 'var_l_16', 'var_l_17',
'var_l_18', 'var_l_20', 'var_l_21', 'var_l_22', 'var_l_23',
'var_l_24', 'var_l_25', 'var_l_26', 'var_l_27', 'var_l_28',
'var_l_29', 'var_l_30', 'var_l_31', 'var_l_32', 'var_l_33',
'var_l_34', 'var_l_35', 'var_l_37', 'var_l_38', 'var_l_39',
'var_l_40', 'var_l_41', 'var_l_42', 'var_l_43', 'var_l_44',
'var_l_45', 'var_l_47', 'var_l_49', 'var_l_51', 'var_l_53',
'var_l_55', 'var_l_57', 'var_l_59', 'var_l_61', 'var_l_62',
'var_l_63', 'var_l_65', 'var_l_67', 'var_l_70', 'var_l_72',
'var_l_75', 'var_l_76', 'var_l_77', 'var_l_78', 'var_l_79',
'var_l_80', 'var_l_81', 'var_l_82', 'var_l_83', 'var_l_84',
'var_l_85', 'var_l_86', 'var_l_87', 'var_l_88', 'var_l_90',
'var_l_92', 'var_l_93', 'var_l_94', 'var_l_95', 'var_l_96',
'var_l_97', 'var_l_98', 'var_l_100', 'var_l_102', 'var_l_104',
'var_l_105', 'var_l_106', 'var_l_108', 'var_l_109', 'var_l_110',
'var_l_112', 'var_l_114', 'var_l_115', 'var_l_116', 'var_l_117',
'var_l_118', 'var_l_120', 'var_l_122', 'var_l_124', 'var_l_126'],
dtype=object),
'corr': array(['var_b25', 'var_b27', 'var_b2', 'var_b28', 'var_b8', 'var_b1',
'var_l_113', 'var_l_74', 'var_b26', 'var_b5', 'var_b4', 'var_l_99',
'var_l_103', 'var_b14', 'var_l_73', 'var_b22', 'var_l_56',
'var_l_101', 'var_l_111', 'var_b12', 'var_l_68', 'var_b11',
'var_l_50', 'var_l_54', 'var_l_121', 'var_b13', 'var_l_66',
'var_l_123', 'var_b24', 'var_b16'], dtype=object)}
(65364, 35)
九、特征分箱
(1)粗分箱
"""
1、*** initalise: ***c = toad.transform.Combiner()
2、*训练分箱*: c.fit(dataframe, y = ‘target’, method = ‘chi’, min_samples = None, n_bins = None, empty_separate = False)
3、*查看分箱节点*:c.export()
4、*手动调整分箱*: c.load(dict)
5、*apply分箱结果*: c.transform(dataframe, labels=False)
labels: 是否将分箱结果转化成箱标签。
False时输出0,1,2…(离散变量根据占比高低排序)
True输出(-inf, 0], (0,10], (10, inf)。
# toad循环所有分箱方法,使用bin_plot函数画出Bivar图,对比单变量的分箱结果
for method in ['chi', 'dt', 'quantile', 'step', 'kmeans']:
c2 = toad.transform.Combiner()
c2.fit(data[['feature', 'label']], y='label', method=method, n_bins=5)
bin_plot(c2.transform(data, labels=True), x='feature', target='label')
"""
# 1、粗分箱
combiner = toad.transform.Combiner()
combiner.fit(train_selected.drop(columns=col_drop), y=target,
method='chi', # 分箱方法: chi-卡方,dt-决策树,kmean-聚类,quantile-等频,step-等长
min_samples=0.05, # 每箱至少包含的样本量,可以是数字或者占比
n_bins=None, # 箱数,若无法分出这么多箱数,则会分出最多的箱数
empty_separate=False # 否将空箱单独分开
)
# 2、查看分箱点
combiner.export()
# 展示部分分箱
print('var_d2:', combiner.export()['var_d2'])
print('var_d5:', combiner.export()['var_d5'])
print('var_d6:', combiner.export()['var_d6'])
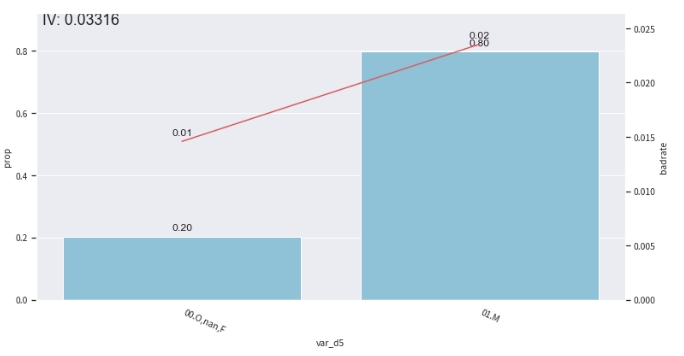
var_d2: [669.0, 748.0, 782.0, 818.0]
var_d5: [['O', 'nan', 'F'], ['M']]
var_d6: [
['PRIVATE LTD COMPANIES', 'PUBLIC LTD COMPANIES',
'PARTNERSHIP FIRM', 'NON-RESIDENT INDIAN', 'nan', 'TRUST'],
['RESIDENT INDIAN', 'HINDU UNDIVIDED FAMILY',
'TRUST-CLUBS/ASSN/SOC/SEC-25 CO.', 'CO-OPERATIVE SOCIETIES',
'LIMITED LIABILITY PARTNERSHIP', 'TRUST-NGO', 'ASSOCIATION',
'OVERSEAS CITIZEN OF INDIA']
]
(2)手动调整分箱
# 3、观察分箱并调整
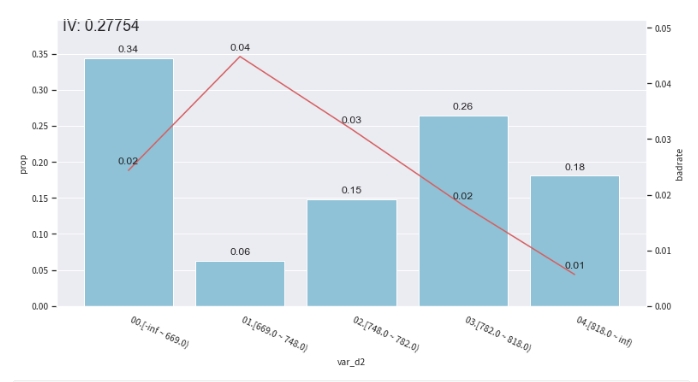
# bar代表了样本量占比,红线代表了正样本占比(e.g. 坏账率)
col = 'var_d2'
bin_plot(combiner.transform(train_selected[[col, target]], labels=True), x=col, target=target)
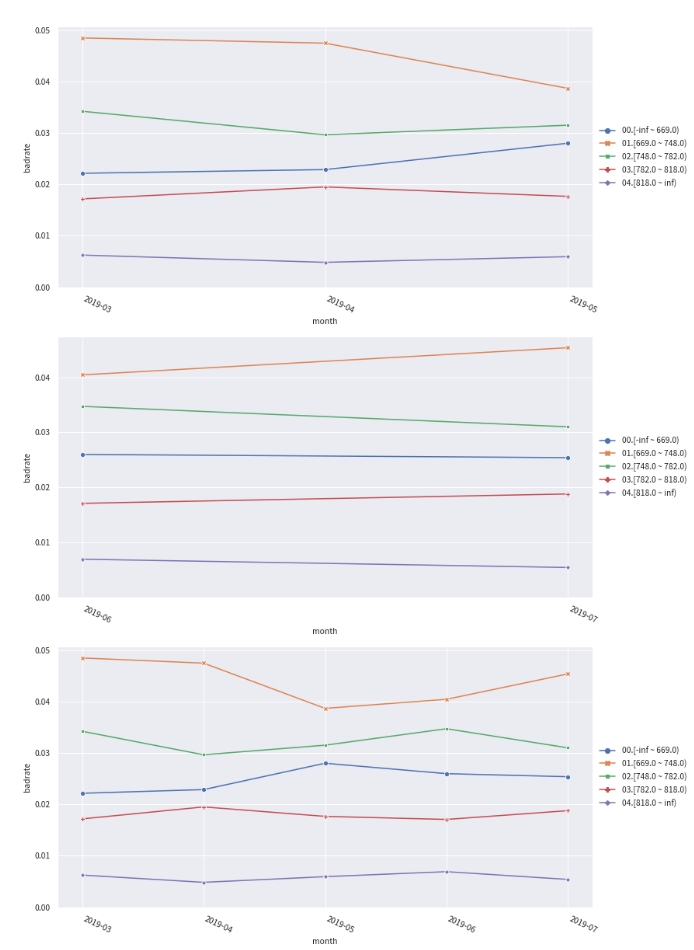
# 跨时间观察--观察每一箱在每个月的badrate是否稳定
badrate_plot(combiner.transform(train[[col, target, 'month']], labels=True), target=target, x='month', by=col)
badrate_plot(combiner.transform(oot[[col, target, 'month']], labels=True), target=target, x='month', by=col)
badrate_plot(combiner.transform(df[[col, target, 'month']], labels=True), target=target, x='month', by=col)
# >>>>>敞口随时间变化而增大为优,代表了变量在更新的时间区分度更强。线之前没有交叉为优,代表分箱稳定。
# 看'var_d5'在时间内的分箱
col = 'var_d5'
# 观察单个变量分箱结果时,建议设置'labels = True'
bin_plot(combiner.transform(train_selected[[col, target]], labels=True), x=col, target=target)
# -- 手动调整分箱
# 设置分组
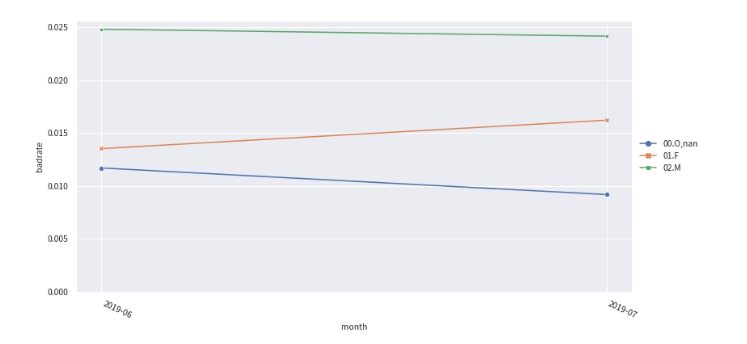
rule = {'var_d5': [['O', 'nan'], ['F'], ['M']]}
# 调整分箱
combiner.update(rule)
# 查看手动分箱稳定性
bin_plot(combiner.transform(train_selected[['var_d5', target]], labels=True), x='var_d5', target=target)
badrate_plot(combiner.transform(oot[['var_d5', target, 'month']], labels=True), target=target, x='month', by='var_d5')
十、woe转化
# 初始化woe transer
transer = toad.transform.WOETransformer()
# 转化
"""
transer.fit_transform(dataframe, target, exclude=None)
训练并输出woe转化的是护具,用于转化train/时间内样本
target: Series 目标列变量
exclude: 不需要被woe转化的列。默认会转化所有的列,包括未被transform的列,通过exclude删去排除列,尤其是target列
transer.transform(dataframe)
根据训练好的transer,转化test/oot数据
"""
# combiner.transform() & transer.fit_transform() 转化训练数据,并去掉target列
train_woe = transer.fit_transform(combiner.transform(train_selected), train_selected[target],
exclude=col_drop + [target])
oot_woe = transer.transform(combiner.transform(oot))
print(train_woe.head(3))
十一、使用PSI再次筛选特征
# ---------- 通过稳定性筛选特征。计算训练集与跨时间验证集的PSI。删除PSI>0.05的特征
data = pd.concat([train_woe, oot_woe])
psi_df = toad.metrics.PSI(train_woe, oot_woe).sort_values(0)
psi_df = psi_df.reset_index()
psi_df = psi_df.rename(columns={'index': 'feature', 0: 'psi'})
psi005 = list(psi_df[psi_df.psi<0.05].feature)
for i in col_drop:
if i in psi005:
pass
else:
psi005.append(i)
data = data[psi005]
dev_woe_psi = train_woe[psi005]
off_woe_psi = oot_woe[psi005]
print(data.shape)
>>> (108940, 35)
十二、相关性筛选特征
# ---------- 由于分箱后变量的共线性会增强,可通过相关性再次筛选特征
train_woe_psi2, drop_lst_2 = toad.selection.select(train_woe, train_woe[target],
empty=0.6, iv=0.02, corr=0.5, return_drop=True, exclude=col_drop)
print("keep:", train_woe_psi2.shape[1],
"drop empty:", len(drop_lst_2['empty']),
"drop iv:", len(drop_lst_2['iv']),
"drop corr:", len(drop_lst_2['corr']))
>>> keep: 19 drop empty: 0 drop iv: 4 drop corr: 12
十三、逐步回归去除多重共线性
"""
toad.selection.stepwise(dataframe, target='target', estimator='ols',
direction='bose', criterion='aic', max_iter=None,
return_drop=False, exclude=None)
estimator: 用于拟合的模型, 'ols'-LinearRegression, 'lr'-LogisticRegression, 'lasso'-Lasso, 'ridge'-Ridge
direction: 逐步回归的方向 'forward', 'backward', 'both'-推荐
critertion: 评判标准,支持 'aic', 'bic', 'ks', 'auc'
max_iter: 最大可迭代次数
return_drop: 是否返回被剔除的变量名
exclude: 不需要被OT出名的列名,比如时间、ID列
经验证,direction='both'时效果最好。
estimator='ols'以及critertion='aic'运行速度最快,且结果对逻辑回归建模有较号的代表性
"""
# 将woe转化之后的数据做逐步回归
df_final_train = toad.selection.stepwise(train_woe, target,
estimator='ols', direction='both',
exclude=col_drop)
十四、训练前准备
# 将选出的变量应用于test/oot数据
df_final_oot = oot_woe[df_final_train.columns]
# 确定建模要用的变量
featurelist = df_final_train.drop(columns=col_drop + [target]).columns.tolist()
# 统计变量PSI,校验woe转化之后的特征稳定性
toad.metrics.PSI(df_final_train[featurelist], df_final_oot[featurelist])
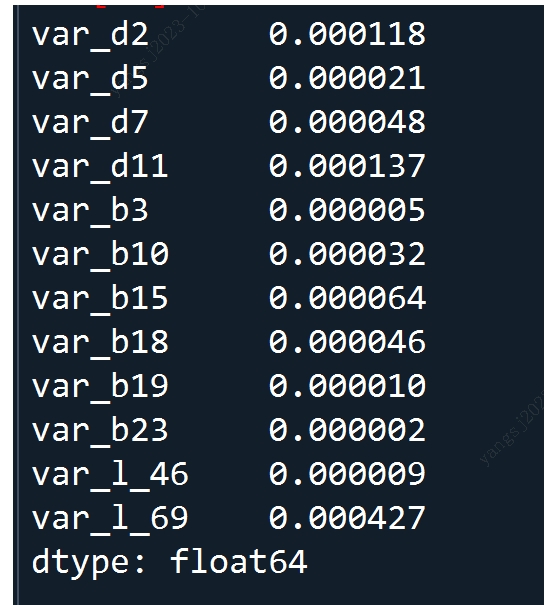
十五、模型训练
# lr & xgb 双向检验
c_train(df_final_train, target=target, exclude=col_drop)
# 评分卡模型训练
lr = LogisticRegression()
lr.fit(df_final_train[featurelist], df_final_train[target])
十六、模型评估
pred_train = lr.predict_proba(df_final_train[featurelist])[:, 1]
pred_oot = lr.predict_proba(df_final_oot[featurelist])[:, 1]
print('训练集')
print('F1:', F1(pred_train, df_final_train[target]))
print('KS:', KS(pred_train, df_final_train[target]))
print('AUC:', AUC(pred_train, df_final_train[target]))
print('跨时间')
print('F1:', F1(pred_oot, df_final_oot[target]))
print('KS:', KS(pred_oot, df_final_oot[target]))
print('AUC:', AUC(pred_oot, df_final_oot[target]))
# ---------- 验证分数PSI稳定性
print(toad.metrics.PSI(pred_train, pred_oot))
print(toad.metrics.PSI(pred_train, pred_oot))
# ---------- 排序性
# 分箱统计各项指标
# toad.metrics.KS_bucket(score, target, bucket=10, method='quantile')
# bucket: 分箱数量 method: quantile-等频 step-等宽
df_train_ksbin = toad.metrics.KS_bucket(pred_train, df_final_train[target], bucket=10, method='quantile')
十七、概率转分数
"""
toad.ScoreCard(combiner={}, transer=None, pdo=60, rate=2, base_odds=20,
base_score=750, card=None, C=0.1, kwargs)
逻辑回归模型转标准评分卡,支持传入逻辑回归参数,进行调参
- combiner: 传入训练好的 toad.Combiner 对象
- transer: 传入先前训练的 toad.WOETransformer 对象
- pdo、rate、base_odds、base_score:
e.g. pdo=60, rate=2, base_odds=20,base_score=750
实际意义为当比率为1/20,输出基准评分750,当比率为基准比率2倍时,基准分下降60分
- card: 支持传入专家评分卡
- **kwargs: 支持传入逻辑回归参数(参数详见 sklearn.linear_model.LogisticRegression)
"""
card = toad.ScoreCard(
combiner=combiner,
transer=transer,
class_weight='balanced',
C=0.1,
base_score=600,
base_odds=35,
pdo=60,
rate=2
)
card.fit(df_final_train[featurelist], df_final_train[target])
# 评分卡在 fit 时使用 WOE 转换后的数据来计算最终的分数
# 分数一旦计算完成,便无需 WOE 值,可以直接使用 原始数据 进行评分。
# 直接使用原始数据进行评分
card.predict(train)
十八、输出评分卡
# 输出标准评分卡
dict_scoreCard = card.export()




 沪公网安备31011302006932号
沪公网安备31011302006932号