- 标签
- 热门文章
- 推荐文章
基于toad库的信用评分卡建模流程
今天和大家分享一个开源的评分卡神器toad库,功能涵盖数据建模中数据探索、特征分箱、特征筛选、WOE变换、模型训练、模型评估和分数转换的全流程。极大简化了建模中最重要且最费时的流程,即特征筛选和分箱。本次分享侧重使用toad进行傻瓜式的评分卡开发流程介绍,模型效果有待进一步通过特征工程优化,数据源同本公众号推送的《基于XGBoost的反欺诈评分模型》。
一、toad库安装
pip install toad
#pip install -i https://pypi.tuna.tsinghua.edu.cn/simple toad
二、toad建模流程
1.导入第三方库及数据
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import toad
from toad.plot import bin_plot
from toad.metrics import KS, F1, AUC, PSI
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
data = pd.read_csv(r"./data/insurance/train.csv")
2.数据探索
使用toad.detector.detect()可以进行EDA分析,数值型变量会返回数据类型、缺失率、唯一值、均值、标准差、分位数等,分类型变量会返回数据类型、缺失率、唯一值、top1(占比第一的数据类)等。
#统计描述
toad.detector.detect(data)
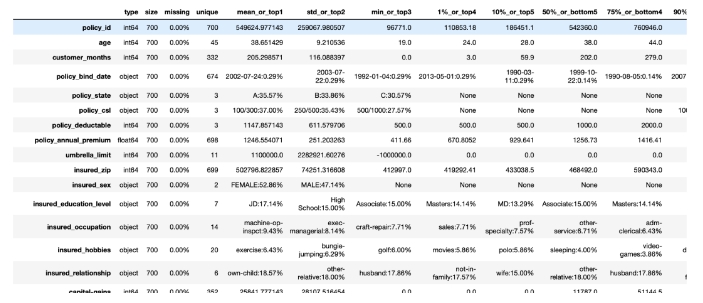
toad.detector.getDescribe()可仅对连续变量进行EDA分析。
#连续变量统计描述
toad.detector.getDescribe(data, percentiles=[.2, .5, .8])

#基于出险日期和保险绑定日期做一个差值,并取出出险日期作为单独的字段
date_list = ['policy_bind_date','incident_date']
for val in date_list:
data[val] = pd.to_datetime(data[val], format = '%Y-%m-%d')
data['detla_time'] = (data['incident_date'] - data['policy_bind_date']).dt.days
#将数字处理成字符
data['picked_month'] = data['incident_date'].dt.month.apply(lambda x: str(x) + '月')
data['property_damage'] = data['property_damage'].map({'?':'nan'})
data['police_report_available'] = data['police_report_available'].map({'?': 'nan'})
data.drop(columns = ['policy_bind_date','incident_date','policy_id'], inplace = True)
object_feature = list(data.select_dtypes(include=['object']).columns)
data = data.drop(columns =object_feature)
target = 'fraud'
Xtr,Xts,Ytr,Yts = train_test_split(data.drop(target,axis=1),data[target],test_size=0.3,random_state=2023)
data_tr = pd.concat([Xtr,Ytr],axis=1)
#增加一列区分训练/测试的特征
data_tr['type'] = 'train'
data_ts = pd.concat([Xts,Yts],axis=1)
data_ts['type'] = 'test'
3.特征选择
toad.quality()查看特征的iv、基尼系数、熵等信息。
#特征筛选
toad.quality(data_tr.drop(columns = 'type'), target)
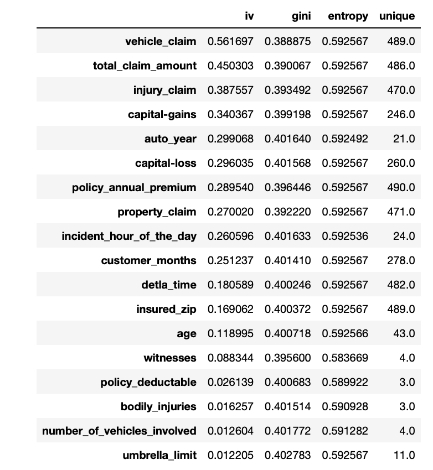
toad.selection.select()根据缺失率、iv值、多重共线性等因素筛选特征。
#组合不同评价指标设置阈值来筛选特征
s_data, d_data = toad.selection.select(data_tr, target=target, empty = 0.8, iv = 0.02
,corr = 0.8, return_drop=True, exclude=None)
s_test = data_ts[s_data.columns]
其中,s_data是保留的特征,d_data是不符合条件的特征,可以发现被剔除的特征主要是由于iv值过低和多重共线性引起。
d_data

toad.detector.detect(s_data)
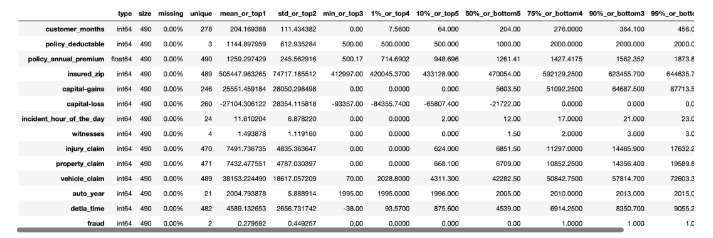
4.分箱工程
toad.transform.Combine对数值型变量和分类型变量进行分箱,支持卡方、决策树、百分位、等频、等距分箱。
4.1自动分箱
#分箱
##初始化Combiner对象
combiner = toad.transform.Combiner()
##fit数据,确定分箱方法
combiner.fit(s_data, y = target, method = 'chi', min_samples = 0.05, exclude = None)
##以字典的形式保存分箱结果
bins = combiner.export()
bins

4.2分箱结果可视化
#分箱结果可视化
for key, value in bins.items():
adj_bin = {}
adj_bin[key] = value
print(adj_bin)
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin)
temp_data = c2.transform(s_data[[key, target]])
##查看各箱体占比
bin_plot(temp_data,x=key,target=target)
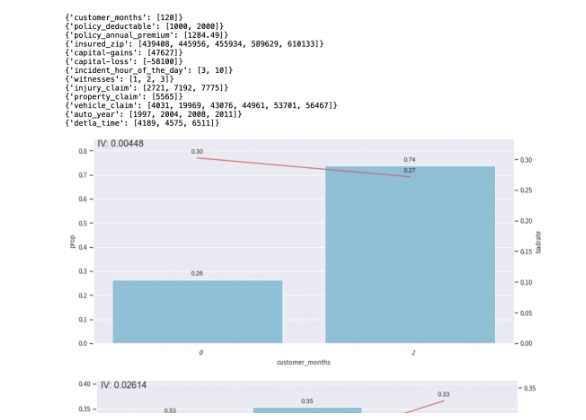
基于以上分箱结果,使用bin_plot()可视化,可以看出insured_zip、witnesses、auto_year等部分特征分箱后的bad_rate不单调,需手动调整分箱进行优化。截图仅列出了部分特征bad_rate。
4.3 手动调整分箱
#insured_zip手动调整分箱
adj_bin1 = {'insured_zip': [445956,589629]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin1)
temp_data1 = c2.transform(s_data[['insured_zip', target]])
bin_plot(temp_data1,x='insured_zip',target=target)
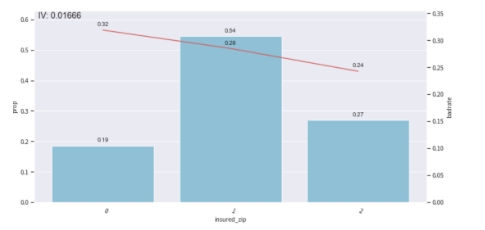
手动对insured_zip分箱进行调整,可以看到调整后的分箱bad_rate呈现单调的趋势。
#incident_hour_of_the_day手动调整分箱
adj_bin2 = {'incident_hour_of_the_day': [1, 10]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin2)
temp_data1 = c2.transform(s_data[['incident_hour_of_the_day', target]])
bin_plot(temp_data1,x='incident_hour_of_the_day',target=target)
#witnesses手动调整分箱
adj_bin3 = {'witnesses': [1, 2]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin3)
temp_data1 = c2.transform(s_data[['witnesses', target]])
bin_plot(temp_data1,x='witnesses',target=target)
#vehicle_claim手动调整分箱
adj_bin4 = {'vehicle_claim': [19969, 56467]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin4)
temp_data1 = c2.transform(s_data[['vehicle_claim', target]])
bin_plot(temp_data1,x='vehicle_claim',target=target)
#auto_year手动调整分箱
adj_bin5 = {'auto_year': [2004, 2011]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin5)
temp_data1 = c2.transform(s_data[['auto_year', target]])
bin_plot(temp_data1,x='auto_year',target=target)
#detla_time手动调整分箱
adj_bin6 = {'detla_time': [4189]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin6)
temp_data1 = c2.transform(s_data[['detla_time', target]])
bin_plot(temp_data1,x='detla_time',target=target)
4.4 分箱转化
#WOE转换
for adj_bin in [adj_bin1,adj_bin2,adj_bin3,adj_bin4,adj_bin5,adj_bin6]:
#设置分箱号
combiner.set_rules(adj_bin)
#将特征值转换为分箱的箱号
binne_data = combiner.transform(s_data)
#计算woe
transer = toad.transform.WOETransformer()
#对woe值进行转换,训练集用fit_transform,测试集用transform
data_train_woe = transer.fit_transform(binne_data, binne_data[target], exclude = target)
data_test_woe = transer.transform(combiner.transform(s_test))
binne_data.head(3)
5.模型训练
toad.selection.stepwise()通过前向、后向、双向选择来进行特征筛选,可使用aic、bic、ks、auc作为选择标准。
#模型特征选择
final_data = toad.selection.stepwise(data_train_woe, target = target
,direction='both', criterion= 'aic')
final_test = data_test_woe[final_data.columns]
print(final_data.shape)
print(final_test.shape)
print(final_data.columns)

#训练集测测试集
Xtr = final_data.drop(target,axis=1)
Ytr = final_data[target]
Xts = final_test.drop(target,axis=1)
Yts = final_test[target]
#训练集测试集变量间的稳定性
toad.metrics.PSI(Xtr,Xts)

#模型训练
lr = LogisticRegression(random_state=2023)
lr.fit(Xtr, Ytr)
#模型评估
##训练集预测
EYtrain_proba = lr.predict_proba(Xtr)[:,1]
EYtrain = lr.predict(Xtr)
##常用的评估指标有F1、KS、AUC
print('train_F1:', F1(EYtrain_proba, Ytr))
print('train_KS:', KS(EYtrain_proba,Ytr))
print('train_AUC:', AUC(EYtrain_proba,Ytr))
##测试集评估
EYtest_proba = lr.predict_proba(Xts)[:,1]
EYtest = lr.predict(Xts)
print('Test error')
print('test_F1:', F1(EYtest_proba,Yts))
print('test_KS:', KS(EYtest_proba,Yts))
print('test_AUC:', AUC(EYtest_proba,Yts))
#模型稳定性
PSI(EYtrain_proba,EYtest_proba)
toad.metrics.KS_bucket()输出模型预测分箱后的评判信息,包括每组分数区间、样本量、坏账率、KS等。
#训练集等频分箱,观察每组区别
train_bucket = toad.metrics.KS_bucket(EYtrain_proba,Ytr,bucket=10,method='quantile')
train_bucket
#测试集等频分箱,观察每组区别
test_bucket = toad.metrics.KS_bucket(EYtest_proba,Yts,bucket=10,method='quantile')
test_bucket
6.评分卡导出
将combiner和traner对象以及模型的超参数传入toad.scorecard.ScoreCard(),就能返回每个特征对应的分数。其中,默认基准分750,且当比率为基准比率2倍时,基准分下降60分。
#评分卡分数变换
card = toad.scorecard.ScoreCard(combiner = combiner, transer = transer , C = 1, random_state=2023)
card.fit(Xtr, Ytr)
card.export(to_frame = True)
上一条:使用toad训练一张评分卡




 沪公网安备31011302006932号
沪公网安备31011302006932号