- 标签
- 热门文章
- 推荐文章
Python数据挖掘-应用toad包中的detect函数进行描述性统计
大数据时代的到来,使得很多工作都需要进行数据挖掘,从而发现更多有利的规律,或规避风险,或发现商业价值。
比如在支付领域,通过挖掘商户的交易数据,分析商户是否有欺诈、盗刷、赌博、套现等风险。
对于有风险的商户,及时进行关闭处理,或者实时中断交易,从而保护个人的资金安全。
在金融领域,通过数据,挖掘客户的偏好和画像,进行新客的拓展和老客的挽留等。
本文和你一起探索数据挖掘常用的函数toad.detector.detect。
本文目录
安装toad包
导入数据
应用detect函数计算描述性统计值
一、安装toad包
首先打开cmd,安装toad包,安装语句如下:
pip install toad
若安装成功,会显示结果如下:
二、导入数据
背景:现需分析53万客户的基本信息和购物信息,用于构建客户的购物画像,预测客户的购物倾向,进行精准营销。
在进行画像分析之前需要对客户的基本信息和购物信息有一个描述性统计。
抽取部分指标用于本文的描述性统计指标展示,具体分析方式如下。
接着导入需分析的数据。
#读取数据
import os
import toad
import numpy as np
import pandas as pd
os.chdir(r'F:\公众号\70.数据分析报告')
date = pd.read_csv('BlackFriday.csv', encoding='gbk')
date.head(5)
展示前几行数据如下:

三、应用detect函数计算描述性统计值
最后,调用toad库下的detect函数,进行数据描述性统计分析,语句如下:
#计算描述性统计值
describe = toad.detector.detect(date)
describe
得到结果如下:
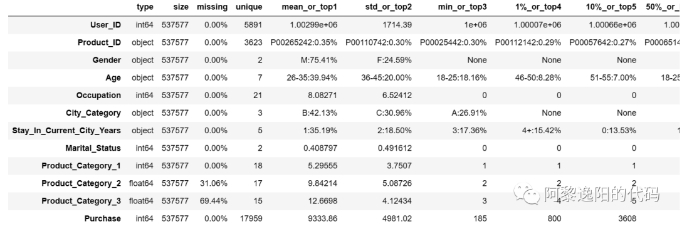
其中index列包含了客户的ID、产品ID、性别、年龄、城市类别、居住在当前城市的年数、产品类别和购买信息等变量名称。
type列展示每个变量的数据类型,包括int型、object型、float型等。
size列描述每个变量的长度。
missing列描述每个变量的缺失率。
unique列描述每个变量的取值个数。
后面的列描述数据的均值、标准差、最值、分位数等信息。
为了更清晰地展示变量对应的统计值,把结果导出到csv文档中,具体语句如下:
describe.to_csv('describe.csv', encoding='gbk')
得到结果如下:

至此,在Python中应用toad.detector.detect进行数据挖掘已经讲解完毕
下一条:抓包神器Fiddler




 沪公网安备31011302006932号
沪公网安备31011302006932号