- 标签
- 热门文章
- 推荐文章
Gurobi优化求解器的基本操作
今天为大家带来的是Python调用Gurobi求解器解决线性规划问题的几个小案例,并且在求解案例的过程中,为大家梳理Gurobi的一些基本操作,争取一篇文章讲透他。
那么,我们开始吧!
问题引入:
对于运筹学的学习,除了掌握基本的建模和求解方法以外,找到合适的求解工具也是必要的。Gurobi就是这样一种求解工具,其作用是为规划问题找出精确解。当然了,如果问题本身是NP难问题,还是需要用启发式算法找到高质量的可行解。
为了帮助大家看明白我接下来在干什么,请大家先看这样一个算例。这个算例来自Gurobi的官方Example--Diet。

这是一个经典的线性规划问题,相信学过运筹的各位都不陌生。我们先来梳理一下要素。
(1)模型参数:食物价格(一维)、每种营养吸收的上下界(一维)、每种食物中每种营养的数量(二维)
(2)决策变量:每种食物的数量(一维)
(3)目标函数:食物总成本
(4)约束条件:每种食物的摄入量在指定区间内
简单写一下这个问题的代数形式,为了方便我就直接用MathType敲完截图过来了。

这里我需要提醒两点,第一,表面上这里我只写了一个约束条件,但实际上每种营养物质都有一个相同形式的约束条件,也就是约束数量和集合的长度是一样的;第二,要想理解后续的求解过程,请确保自己理解第一点和此处约束中求和符号的含义,因为Gurobi可以根据这些批量地生成相同形式的约束。
接下来我将层层递进地为大家讲解如何求解这个问题, 本文目录如下。
Gurobi是啥?
Gurobi的数据结构
从案例中学会基本操作
一、Gurobi是个啥
我们先来看一下官方对Gurobi的介绍吧。
Gurobi是由美国Gurobi公司开发的用于求解线性模型(LP)、二次型模型(QP)、混合整数线性模型(MIP)的大规模数学规划优化器,在Decision Tree for Optimization Software网站举行的第三方优化器评估中, Gurobi展示出更快的优化速度和更高的求解精度,成为优化器领域的新翘楚. Gurobi采用最新优化技术,充分利用多核处理器优势,其任何版本都支持并行计算.它提供了方便轻巧的接口,支持C++、JAVA、Python、. Net开发,内存消耗少,且支持多目标优化、支持包括SUM、MAX、MIN、AND、OR等广义约束和逻辑约束、支持多种平台和建模环境. Gurobi为学校教师和学生提供了免费版本,其优化性能显著超过传统优化工具。(参考自殷允强老师《整数规划》)
这里面提到的免费版本,大家可以去下面这个网址里面自行查看。安装的具体步骤网上已经挺多了,这里就不再赘述啦!(这里再多说一句,Gurobi可以为在校生或教师提供IP认证,如果不在学校,需要额外提供相应的证明噢)
http://www.gurobi(搜索的时候删掉括号).cn/NewsView1.Asp?id=4
Gurobi的一个很好用的点在于,它定义了两种扩展对象数据结构,即TupleList和TupleDict,这在大规模的问题中可以极大提高求解效率,因为Tuple(元组)数据结构不可更改。以元组的形式存储数据,适合存储决策变量与参数的多维下标。
二、Gurobi的数据结构
刚才我们提到的两种数据结构长啥样?先给大家一个直观的了解。
图1

图2

简单来说,Tuplelist就是一个元组的列表(这个从名字就能看出来!),也可以理解为我们问题中实体(用程序员黑话说就是对象)的集合。Tupledict就是以一个元组为Key的字典。
那么,这两种数据结构我们怎么用呢?我们在两个地方需要用到它们:决策变量和模型参数。决策变量的使用我会在第三小节介绍,模型参数的赋值一般可以使用Gurobi内置的Multidict()函数。
接下来我们手动导入开篇案例需要的参数,首先是每种食物的价格。
# 导入我们的新朋友们
import gurobipy as gp
from gurobipy import GRB
# 这个就是multidict的使用方法,需要调用gurobipy包。
foods, cost = gp.multidict({
'hamburger': 2.49,
'chicken': 2.89,
'hot dog': 1.50,
'fries': 1.89,
'macaroni': 2.09,
'pizza': 1.99,
'salad': 2.49,
'milk': 0.89,
'ice cream': 1.59})
是不是有点懵?foods和cost都是方法multidict的返回值(鉴于我的读者中熟悉Java的比较多,这里还是解释一下,Python里的函数和方法都是允许多个返回值的)。这么一顿操作下来foods是一个Tuplelist,存储每种食物的名字,cost是一个Tupledcit,它的keys是食物的名字,values对应食物的价格。让我们来看看输出以后长啥样吧。

也就是说,第一列存进了数据结构为Tuplelist的foods里面,然后这两列分别作为key和value存进了数据结构为Tupledict的cost里。
我们继续导入每种营养物质的上下界限。
categories, minNutrition, maxNutrition = gp.multidict({
'calories': [1800, 2200],
'protein': [91, GRB.INFINITY],
# GRB.INFINITY的含义是无穷大。蛋白质的摄入量没有上限,可能是合理的。
'fat': [0, 65],
'sodium': [0, 1779]})
诶,这里怎么多了一列?这个时候你发现,原来Value的位置可以写成列表!在这种写法下,打头的categories仍然是Tuplelist,所有列表的第一列存入了第一个Tupledict--minNutrition,第二列存进了第二个Tupledict--maxNutrition。输出结果如下。

接下来导入每种食物中每种营养的数量。
nutritionValues = {
('hamburger', 'calories'): 410,
('hamburger', 'protein'): 24,
# 以下省略,单纯穷举
# 完整数据可以去看Gurobi官方案例文档
}
这里展示了另一种更为直接的给Tupledict赋值的方式,本质上还是一样的,只不过由于这个参数有两个下标,Tupledict的keys是个二元组。这就是多下标参数的处理方法,Gurobi处理这种数据结构的效率很高。导入的数据长这样:

三、跟着案例学基本操作
当我们使用Gurobi求解模型时,步骤和我上面分析开篇案例时建模的逻辑是相同的。下面这张图展示了这个过程和每个步骤调用的方法。

拿步骤1添加决策变量的addVar()和addVars()两个方法为例,前者一次可以生成一个决策变量,而后者可以一次生成多个,其格式可以复制已经创建好的某个Tuplelist或Tupledict(这段看不懂无所谓,往后看自然就明白了)。
我们先按照这套逻辑,两个简单的例子。(大家不要嫌我啰嗦哈,不然后面解决开篇案例可能就看不懂了!)
案例一:一个普普通通的整数规划
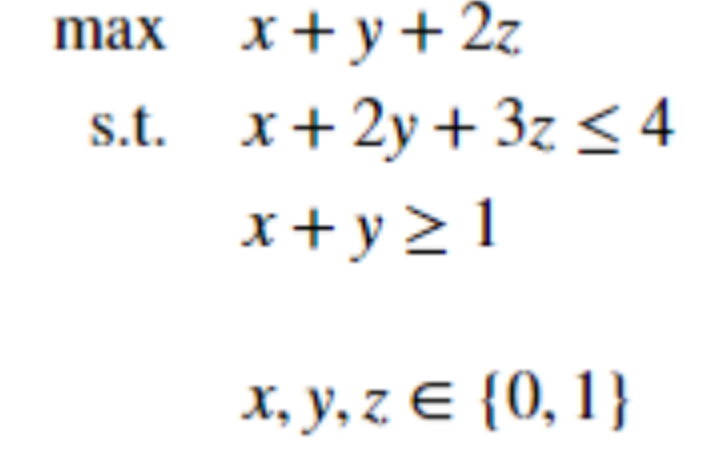
代码如下,注释已经写得比较清楚啦:
# 导入我们的老朋友们
import gurobipy as gp
from gurobipy import GRB
# 隐藏的第一步:实例化一个模型!!
m = gp.model('e1')
# 第一步:创建变量
# 这里分别建立他们仨,vtype描述了这个变量的取值:
# BINARY代表的是二进制,INTEGER代表整型,不写就是连续型
x = m.addVar(vtype=GRB.BINARY,name='x')
y = m.addVar(vtype=GRB.BINARY,name='y')
z = m.addVar(vtype=GRB.BINARY,name='z')
# 第二步:写出目标函数!
# 事实上,这个写法对人类还是很友好的,直接敲进去就可以啦
#后面的MAXIMIZE或者MINIMIZE代表目标取最大or最小
m.setObjective(x+y+2*z,GRB.MAXIMIZE)
# 第三步:创建约束条件
# 这里的约束比较简单,所以挨个输入就可。
# 这个写法也是比较符合人类的习惯的,所以应该能看得懂,不再过多解释
m.addConstr(x+2*y+3*z <= 4,'c0')
m.addConstr(x+y >= 1,'c1')
# 第四步:优化!模型m调用optimize()方法,就可以对现有的模型进行求解啦
m.optimize()
运行程序,你会看到如下的结果。

这个结果看不懂!那就简单点,用我们能看懂的方式输出结果。
for v in m.getVars():
print('%s %g' % (v.varName,v.x))
print('Obj:%g' % m.objVal)
结果如下
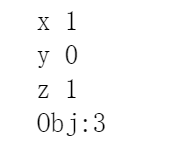
看!我们解决了第一个问题了耶!现在我们可以去解决最开始的问题了嘛?
答曰:不行!因为这个问题太简单了,就连求和操作都没用到。我们再看一个案例吧!
案例二:一个稍微复杂的整数规划
我们再来看一个案例,我保证这是最后一道开胃菜啦。

不过,处理这个问题我们得一步步地拆开来看。这里我们假设,已经完成了Tuplelist结构的
、
集合和Tupledict结构的参数 的实例化和赋值,集合
、
中元素个数分别为
、
。
(1)建立决策变量
# 再次导入我们的老朋友们
import gurobipy as gp
from gurobipy import GRB
# 建立模型
m = gp.model('e2')
# 建立决策变量
x_ij = m.addVars(c_ij,GRB.BINARY,name='x')
注意看,这里我选择了addVars(),也就是批量生成多个决策变量。这个方法的第一个参数是已经有的Tupledict ,意思就是生成一个和 的Keys相同的Tupledict 。
(2)设定目标函数
有意思的地方来了!这个例子中的目标函数需要进行两次求和,而Gurobi为了提升这一步的效率,使用的是quicksum()函数,基本原理是按照循环的方式对里面的各项进行累加,就像下面的第一种写法。
# 第一种写法
m.setObjective(quicksum(c_ij[i][j]*x_ij[i][j] for i in I for j in J),GRB.MINIMIZE)
当然了,这种比较简单的求和形式,也可以直接调用Tupledict的prod()方法,能够起到一样的效果。
# 第二种写法
m.setObjective(x_ij.prod(c_ij),GRB.MINIMIZE)
(3)构建约束条件!
我们先来看第一个约束。
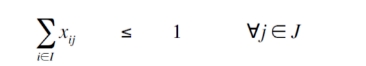
这个约束对应集合中的各个实体,都是对集合求和,所以约束的数量共有 个。求和的操作可以使用Tupledict的sum()方法,这个方法的各个参数分别对应这个字典的Keys中元组中的各项。
接下来我们挨个导入约束,看一下sum的使用吧。
# 建立约束 -- sum的使用
m.addConstr(x_ij.sum('*',1) <= 1)
m.addConstr(x_ij.sum('*',2) <= 1)
m.addConstr(x_ij.sum('*',...) <= 1)
m.addConstr(x_ij.sum('*',n) <= 1)
注意到sum的第一个参数是 '*',意思是在 的下标确定的情况下,对 i 集合的各个元素求和。所以上面代码的就相当于完成了以下约束的引入。
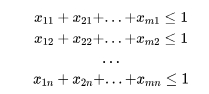
这个时候你可能会想,如果是个大规模的问题,涉及到成千上万个约束条件,难道也是这样一个个地导入么?
当然不是啦,和导入决策变量一样,约束条件也是可以批量导入的。addConstrs()这个方法生成多个约束靠的是for循环。所以生成两个约束的代码如下。
m.addConstrs(x_ij.sum('*',j) <= 1 for j in J)
m.addConstrs(x_ij.sum(i,'*') <= 1 for i in I)
如果大家对Python足够熟悉,这个代码应该很容易理解,因为它就等同于:
for j in J:
m.addConstr(x_ij.sum('*',j) <= 1)
for i in I:
m.addConstr(x_ij.sum(i,'*') <= 1)
如果需要写多个for循环,直接在约束式后面按顺序添加即可,比如下面这俩也是等同的。
# 第一种
m.addConstrs(x_ij.sum(i,j) <= 1 for j in J for i in I)
# 第二种
for j in J:
for i in I:
m.addConstr(x_ij.sum(i,j) <= 1)
(4)求解!
好了,所有的条件都导入完毕了,进入最后一道工序:求解。
m.optimize()
经过这个案例,相信大家已经对模型必备要素的导入和生成,以及quicksum、prod、sum这些方法都轻车熟路了。接下来我们终于可以解决开篇的案例了!
案例三:营养均衡身体倍棒
来不及解释了直接开冲!
(1)建立模型和决策变量
# 这个不用再写注释了吧!
m = gp.Model("diet")
# 第一个参数是foods,也就是代表决策变量的Tupledict的Key和foods相同
buy = m.addVars(foods, name="buy")
(2)两种写法建立目标函数
# 写法一:极致简洁
m.setObjective(buy.prod(cost), GRB.MINIMIZE)
# 写法二:初学者可用
m.setObjective(sum(buy[f]*cost[f] for f in foods), GRB.MINIMIZE)
(3)写入约束条件
# 下界
m.addConstrs((gp.quicksum(nutritionValues[f, c]
* buy[f] for f in foods)
>= minNutrition[c] for c in categories), "c1")
# 上界
m.addConstrs((gp.quicksum(nutritionValues[f, c]
* buy[f] for f in foods)
<= maxNutrition[c] for c in categories), "c2")
这个地方其实有个需要注意的地方。和案例2不同,案例2中决策变量的下标是连续型的,所以可以直接写小星星代表对全部加和。但是本案例决策变量的下标并不是连续型,集合内的元素也有实际意义,所以最好还是使用quicksum带内部循环的方式写入约束。
当然了,上下界的约束各写成一行代码还是麻烦了点,所以这个约束条件还可以写成下面这样。
m.addConstrs((gp.quicksum(nutritionValues[f, c] * buy[f] for f in foods)
== [minNutrition[c], maxNutrition[c]]
for c in categories), "c0")
妙哇!这样我们就可以直接求解了!
(4)求解与Output
继续调用我们的老朋友进行求解。
m.optimize()
接下来写一个输出结果的函数,仔细看!
def printSolution():
# 检查模型状态,是不是有解?GRB.OPTIMAL == 2
if m.status == GRB.OPTIMAL:
# 输出目标值
print(' Cost: %g' % m.objVal)
print(' Buy:')
# 输出决策变量的求解结果,注意.x这个表达
for f in foods:
if buy[f].x > 0.0001:
print('%s %g' % (f, buy[f].x))
# 包含没有解的情况(Infeasible or Unbounded etc.)
# m.status == 3表示无可行解
else:
print('No solution')
利用这个函数输出结果如下。
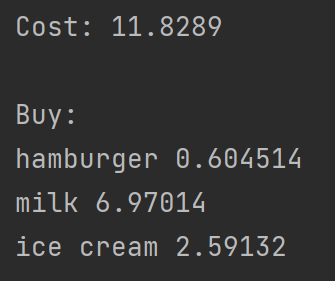
这样,这个手算相当复杂的问题就被计算机在0.00秒之内解决了!
如果大家从头看到这里并且跟着做的话,会发现Gurobi其实还是蛮好上手的,甚至会因为一些神奇的设计而拍案叫绝。这是因为Gurobi的表达方式和人类对于此类问题的表达习惯是基本一致的。
上一条:gurobi能求解多大规模的问题




 沪公网安备31011302006932号
沪公网安备31011302006932号